


Advance healthcare DevOps and infrastructure engineering
Telehealth usage jumped from 11% in 2019 to 46% in April 2020, a 300% increase, as healthcare systems had to support remote care at speed during the pandemic, according to DevOps.com’s healthcare DevOps case study. That single shift exposed a hard truth. Legacy infrastructure that was tolerable in stable conditions became a liability when patient demand, clinical workflows, and security pressure changed all at once.
That’s why healthcare DevOps and infrastructure engineering matters now. This isn’t about borrowing startup language and applying it to hospitals or digital health platforms. It’s about building systems that can release safely, recover predictably, and prove compliance without depending on heroics from one operations engineer or a stack of manual approvals.
Traditional healthcare IT often breaks at the seams in familiar ways. Environments drift. Security checks arrive late. Release windows get scheduled around fear rather than confidence. Teams delay needed updates because nobody wants to touch a brittle deployment path tied to patient data, integrations, or billing flows.
Modern healthcare platforms need a different operating model. They need versioned infrastructure, automated delivery controls, observability that catches issues early, and security that starts in the pipeline rather than after deployment. That’s the practical center of this guide.
The New Imperative for Modern Healthtech
Software now sits on the critical path of care delivery. A patient cannot complete intake, join a virtual visit, refill a prescription, or receive a lab update if the platform behind that workflow is slow, brittle, or misconfigured.
Healthtech teams have responded by adopting more automation, CI/CD, and cloud tooling. The hard part is implementation. In healthcare, DevOps only works when delivery practices are tied to HIPAA controls, audit evidence, identity boundaries, and clear ownership for systems that handle PHI.
That changes the engineering brief. The goal is not faster shipping by itself. The goal is to release changes to patient data systems with repeatable controls, reliable rollback, and enough traceability to satisfy security, compliance, and operations at the same time.
In practice, three forces are pushing teams to rebuild their operating model:
- Digital care is now core infrastructure: Telehealth, patient apps, device integrations, and clinician-facing workflows have become production systems with uptime and latency expectations.
- Hybrid environments are the norm: Many providers and healthtech vendors still run a mix of on-prem systems, managed cloud services, and third-party clinical platforms. That creates real integration and policy enforcement challenges.
- Manual compliance does not scale: Spreadsheet-based evidence collection, ticket-driven approvals, and one-off access reviews break down once release frequency increases.
The trade-off is straightforward. Manual processes can feel safer because more people touch each step. They also create inconsistent environments, slow incident response, and weak audit trails. Automated controls require more upfront engineering, but they give teams a system they can test, review, and repeat.
I have seen the same pattern across payer, provider, and digital health platforms. Teams struggle less with writing application code than with the infrastructure around it: how secrets are managed, how environments are reproduced, how production access is limited, and how change records are generated without forcing engineers back into manual work.
That is why healthcare DevOps has to be designed around security from the start. Agile and DevOps practices are useful, but generic playbooks miss the constraints that shape healthtech platforms. Data residency, BAA boundaries, EHR dependencies, legacy workloads, and HITRUST evidence requirements all affect the architecture.
Organizations planning broader platform changes usually run into the same conclusion described in this guide to healthcare digital transformation. Product modernization, infrastructure engineering, and compliance work have to move together. If they happen in sequence, delivery slows down and control gaps show up late, when fixes are more expensive.
The Foundations of Healthcare DevOps
Healthcare delivery systems fail in predictable ways when infrastructure is improvised. Releases slow down, environments drift, evidence goes missing, and production access expands over time because no one designed a better path. Healthcare DevOps exists to prevent that pattern.
The goal is not release speed by itself. The goal is controlled change in systems that store, process, or transmit patient data across cloud services, hospital networks, third-party APIs, and legacy platforms. Generic DevOps advice rarely covers that reality. Healthtech teams have to build pipelines and platforms that satisfy engineering needs and stand up to HIPAA, HITRUST, and internal risk review at the same time.
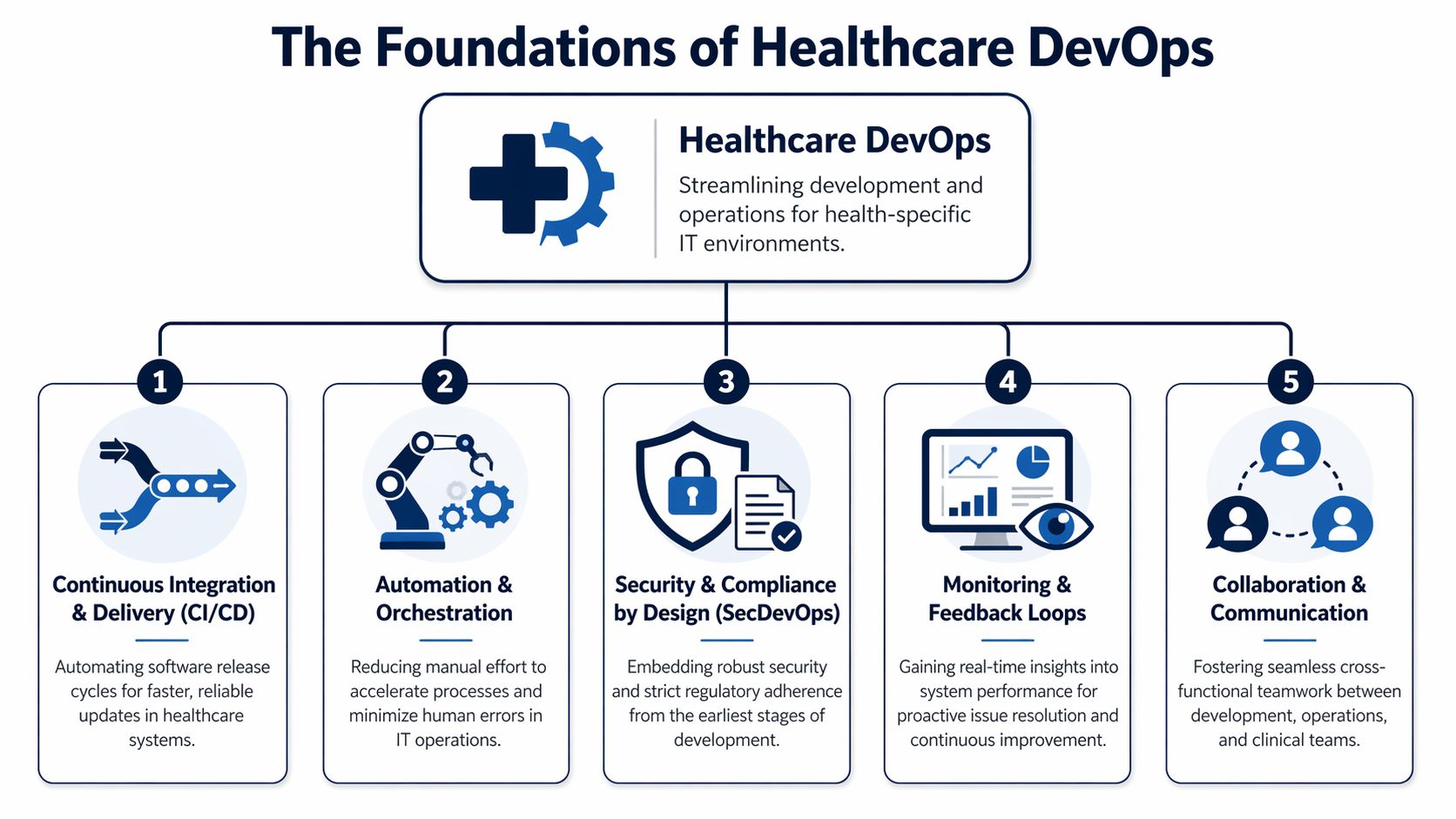
CI and CD as the controlled change path
Continuous Integration and Continuous Delivery give teams a repeatable route from commit to production. In healthcare, that route has to do more than run tests and deploy containers. It also has to enforce separation of duties, preserve evidence, and reduce the chance that a late-night fix for one workflow breaks another system tied to patient care or claims operations.
A workable healthcare CI/CD design usually includes:
- Automated validation: Unit, integration, policy, and security checks run before code is promoted.
- Immutable artifacts: The build tested in one environment is the same build promoted to the next.
- Approval controls: High-risk changes require defined reviewers, not ad hoc Slack approvals.
- Rollback planning: Teams decide in advance whether they will roll back, fail over, or disable a feature flag.
Teams that are still aligning release discipline with engineering practice can use this overview of Agile and DevOps practices as a baseline. In healthcare, the harder part is adding compliance-aware controls without turning the pipeline back into a manual ticket queue.
IaC as the source of operational truth
Infrastructure as Code is the line between a platform that can be audited and one that depends on memory. Networks, IAM policies, Kubernetes clusters, databases, DNS records, and backup settings should all be declared in code, reviewed in pull requests, and promoted through the same workflow as application changes.
That matters even more in hybrid environments. Many healthcare organizations run part of the stack in cloud infrastructure, part in private data centers, and part through managed vendors with contractual and data boundary constraints. IaC gives teams a way to standardize what they control and clearly document what they do not.
A practical rule applies here. If an environment cannot be rebuilt from code, it is not under full control.
In day-to-day operations, IaC supports:
- Environment parity: Staging reflects production closely enough to test real deployment risk.
- Traceable change history: Git records who changed a security group, subnet rule, or IAM role and why.
- Faster recovery: Teams can recreate damaged infrastructure without relying on console screenshots.
- Cleaner audits: Reviewers can inspect declared state instead of reconstructing it after the fact.
This discipline becomes especially important in healthcare software development programs that need compliant infrastructure patterns.
SRE as the reliability control system
Site Reliability Engineering gives healthcare teams a way to make uptime decisions based on service impact instead of noise. A patient scheduling API, an eligibility verification service, and an internal reporting dashboard should not share the same service level objective, paging policy, or recovery target.
Good SRE practice starts with classification. Which services affect clinical workflows? Which ones affect revenue cycle timing? Which failures are annoying, and which ones stop care delivery, delay lab results, or block patient access?
From there, teams build observability around the systems that matter most. That usually means metrics, logs, traces, synthetic checks, and alert thresholds tied to user-facing risk. Error budgets help too, but they need context. In a consumer app, burning the budget might mean slowing feature work for a sprint. In a patient data system with unstable integrations, it can mean freezing deployments until interface reliability and incident response improve.
Platform collaboration is an architecture decision
Healthcare DevOps breaks down when engineering, security, compliance, and operations each run separate workflows and reconcile them at the end. The stronger model is shared platform ownership with clear control points.
That does not mean every team uses the same backlog or approves the same changes. It means infrastructure standards, access controls, deployment policy, logging requirements, and evidence collection are designed as one operating model. Teams get fewer surprises that way. Security reviews happen earlier. Audit preparation gets easier. Hybrid cloud and on-prem dependencies stop being afterthoughts.
The foundation is simple to describe and harder to implement. Build delivery around repeatable pipelines, codified infrastructure, measurable reliability, and shared controls. In healthcare, those are not process upgrades. They are the operating requirements for shipping safely at scale.
Navigating the Compliance and Security Maze
Healthcare security failures are patient safety failures. Industry reporting after major healthcare cyber incidents has tied outages to delayed care, poor clinical outcomes, and, in some cases, increased mortality. That is the operating context for infrastructure decisions in this field. Compliance is not paperwork around the platform. It is part of how the platform is built.

Speed without control creates rework. Control without automation creates bottlenecks. Healthcare teams need both, especially when HIPAA, HITRUST, vendor risk reviews, and internal security standards all apply to the same delivery path.
Shift security left into the pipeline
Security review has to start before a build artifact exists. In practice, that means engineers get feedback in pull requests, CI jobs, container image scans, and deployment policy checks, not in a late-stage ticket from a separate review queue.
A workable model usually includes:
- Static analysis before merge: Catch insecure coding patterns while the change is still easy to fix.
- Dynamic and runtime-oriented testing later in the path: Validate behavior that only shows up during execution.
- Secret scanning in source and build systems: Stop exposed credentials before they become an incident.
- Policy enforcement in deployment workflows: Block releases that fail control requirements, with exceptions logged and approved through a defined path.
The trade-off is real. More gates can slow delivery if every check runs on every change. Strong teams classify controls by risk. A UI text change should not wait on the same path as an identity service update that touches patient access. If your team is formalizing that model, a secure software development lifecycle for regulated delivery teams is a useful reference point.
Make PHI handling explicit
A surprising number of delivery problems start with vague assumptions about where protected health information is allowed to exist. That ambiguity shows up in test data copies, debug logs, analyst exports, and third-party tools added for convenience.
Set the boundary in code and policy:
- Encrypt data at rest and in transit: Apply it to databases, object storage, message queues, backups, and service-to-service traffic.
- Reduce PHI in non-production environments: Prefer synthetic or masked data. Allow realistic datasets only where the use case justifies the risk and the access model is tightly controlled.
- Keep secrets out of code and pipeline variables: Use managed secret stores with rotation, access logging, and short-lived credentials where possible.
- Design logs for traceability without exposure: Record who did what and when, but suppress sensitive fields before they reach log pipelines, traces, dashboards, or paging tools.
Hybrid reality matters. Many healthcare organizations still run core systems on-premises while newer services deploy in cloud platforms. The safest pattern is not to copy PHI broadly so every environment has what it needs. It is to minimize movement, isolate trust zones, and make every approved data flow visible.
Turn audits into delivery artifacts
Audit pain usually points to an engineering gap. If evidence lives in screenshots, email approvals, and manually updated spreadsheets, the process will break under release pressure.
Compliance as code fixes that by putting controls inside the same systems that manage infrastructure changes. Git history shows who changed a network policy. CI records show which checks passed. Artifact registries show what was built and promoted. IAM reviews become easier when role definitions, approval paths, and expiration rules are versioned instead of managed informally.
For healthcare teams, that approach works best when the control set is specific:
| Control area | Strong practice |
|---|---|
| Infrastructure changes | Managed through Terraform or Pulumi with peer review and policy checks |
| Release approvals | Enforced in CI/CD with named approvers and recorded exceptions |
| Secrets | Stored, rotated, and audited outside application code |
| Access | Scoped with least privilege, role-based controls, and periodic review |
| Evidence | Captured automatically in Git history, build records, registry logs, and cloud audit trails |
There is also a cost dimension. Security controls that sprawl across oversized instances, idle environments, and unnecessary replicas become harder to monitor and justify. Cost discipline helps security when it removes waste and reduces attack surface. Teams that need a practical starting point can use AWS EC2 Right Sizing for cost optimization to trim excess capacity without weakening operational guardrails.
The end goal is straightforward. Build a delivery system where compliant behavior is the default path, exceptions are rare and visible, and patient data protections survive the realities of hybrid infrastructure, frequent change, and audit scrutiny.
Architecting for Scalability and Resilience
Hybrid infrastructure remains the sticking point for a large share of healthcare organizations. The pattern is consistent across provider groups, digital health platforms, and payer environments. Teams want cloud speed and managed services, but they still carry local systems that cannot move easily because of data residency rules, device integration, imaging workloads, or latency-sensitive clinical workflows.
That reality shapes architecture more than preference does.
The design question is not whether cloud is better than on-premises. The design question is where each workload belongs, how failure is contained, and how patient data stays protected while systems scale. In healthcare, resilience also has a compliance dimension. An outage that delays chart access, medication workflows, or patient messaging becomes an operational risk fast. A scaling mistake that copies protected data into the wrong environment becomes a security incident.
Choosing between on-prem, cloud, and hybrid
Each model can work. The trade-offs are different, and they affect operations long after the migration plan is approved.
On-premises still fits systems that depend on hospital networks, local devices, tightly coupled legacy applications, or data handling constraints that an organization is not ready to address in the cloud. The cost is slower elasticity and a larger internal operations burden.
Cloud fits new digital products, API platforms, asynchronous data processing, analytics pipelines, and workloads with variable demand. Teams get faster provisioning, managed services, and easier regional expansion. They also inherit new failure modes, cost exposure, and a stronger need for guardrails around identity, networking, and data movement.
Hybrid cloud is often the practical answer for established healthcare estates. Keep systems of record, device-adjacent services, or latency-sensitive components close to the data center. Run internet-facing applications, event processing, and platform services in the cloud. That split only works if identity, observability, change control, and encryption standards are consistent across both sides.
Here is the architecture view I use with healthcare teams.
Healthcare Infrastructure Architecture Comparison
| Criterion | On-Premises | Cloud (Public/Private) | Hybrid Cloud |
|---|---|---|---|
| Data sovereignty control | Strong local control | Depends on provider configuration and region strategy | Flexible when sensitive workloads stay local |
| Latency for clinical systems | Often best for tightly coupled local systems | Good for broadly distributed digital services | Useful when some workflows need local speed |
| Elastic scaling | Limited by owned capacity | Strong, especially for bursty demand | Strong if traffic routing and dependencies are well designed |
| Operational complexity | High internal ownership burden | Lower hardware burden, higher platform governance need | Highest design complexity because both worlds must align |
| Auditability | Achievable, but often more manual in legacy estates | Strong with mature cloud guardrails and IaC | Strong if standards apply consistently across both environments |
| Legacy integration | Usually easiest | Sometimes difficult without adapters or redesign | Often the most realistic transition path |
| Cost predictability | Stable but capital-heavy | Flexible but easy to overspend without governance | Mixed. Needs strong financial and platform discipline |
Resilience engineering starts with dependency mapping. Before scaling a service, identify its upstream systems, downstream consumers, data stores, authentication path, and failure behavior. In healthcare, I look for hidden single points of failure first. Common examples include one interface engine shared by many clinical workflows, a central identity dependency with no degraded mode, or a legacy database that every new service still calls synchronously.
Why microservices help and where they hurt
Microservices make sense when service boundaries match real business domains and different parts of the system need to change at different rates. Scheduling, claims, patient notifications, consent, clinical document exchange, and analytics rarely have the same release cadence. Separating them can reduce coordination overhead and limit the scope of testing for routine changes.
The benefits are practical:
- Independent releases: A reminder service can ship without waiting on a billing deployment window.
- Targeted scaling: High-volume APIs or queue consumers can scale without increasing capacity for the whole platform.
- Smaller failure domains: One service can degrade without taking down every user path.
The costs are also practical. Teams need service ownership, API versioning discipline, distributed tracing, and clearer runbooks. Cross-service calls introduce latency and retry storms if they are not designed carefully. Data consistency gets harder when transactions span multiple systems. Healthcare teams also need to decide where protected health information is allowed to flow. A service split that looks clean in a diagram can create audit and access control problems if patient data becomes scattered across too many stores.
A monolith is often the better choice early on if one team owns the product, the deployment cadence is manageable, and the system boundaries are still changing. Split only where there is a measurable gain in release independence, scale isolation, or fault isolation.
Containers and orchestration as the execution layer
Containers solve a basic but expensive problem. They reduce runtime drift between environments. In regulated healthcare systems, that matters because production issues are harder to investigate when every environment behaves differently.
Kubernetes or another orchestrator helps when you need controlled rollouts, self-healing, service discovery, and standardized deployment behavior across many services. It is not the default answer for every team. Small platforms with a few stable services can run well on simpler managed compute options. Kubernetes earns its place when the operational consistency outweighs the platform overhead.
The security model matters as much as the scheduler. Use separate namespaces or clusters based on trust boundaries. Enforce network policies. Store secrets outside application code. Restrict service account permissions. Scan container images before promotion, not after deployment. For patient data systems, these controls are part of the architecture, not cleanup work.
Scale settings also need restraint. Auto-scaling can absorb traffic spikes, but poor resource requests and oversized nodes waste budget and hide inefficient code paths. Cost discipline supports resilience because it forces teams to understand workload behavior instead of masking it with excess capacity. A useful starting point is AWS EC2 Right Sizing for cost optimization, especially for teams running mixed node pools or carrying inflated baseline capacity after an initial migration.
The strongest healthcare platforms are boring in the right places. Infrastructure is reproducible. Failure modes are known. Recovery steps are tested. Sensitive data stays inside defined boundaries even when services scale, fail over, or deploy several times a day.
Your Implementation Roadmap from Pilot to Scale
Healthcare teams that try to scale DevOps before they have one audited, repeatable delivery path usually create more variance, not more speed. In regulated environments, that variance shows up fast. Controls drift between teams, approvals stay manual, and patient data risks get buried inside exceptions.
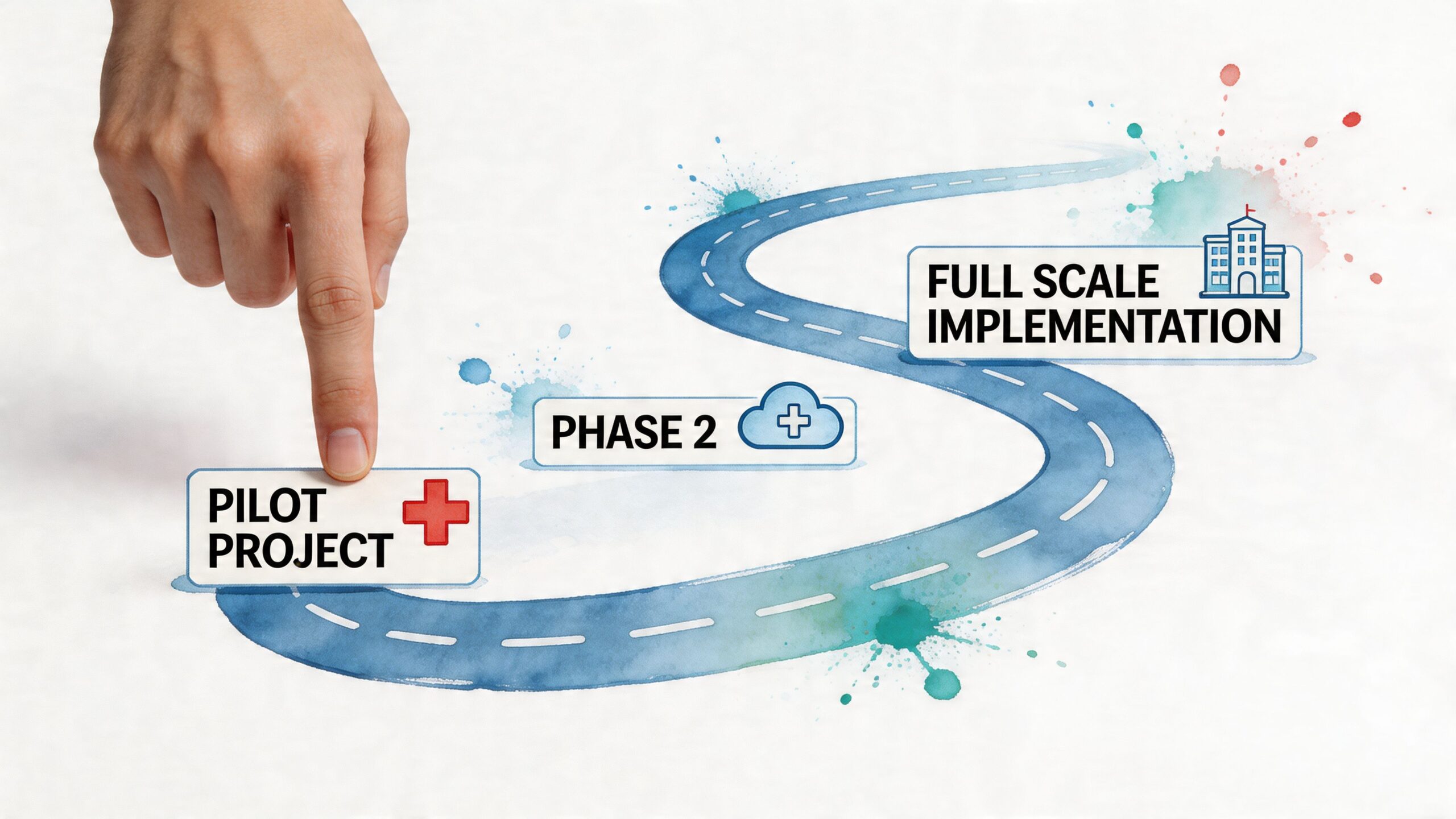
A usable roadmap starts smaller. Pick one service, one team, and one production release path. Then prove that delivery, auditability, and security controls hold up under healthcare operating conditions, including access reviews, incident response, and evidence collection for HIPAA or HITRUST-aligned programs.
Phase one builds the operating core
Start with ownership before tooling. If nobody can answer who owns deployment policy, cloud identity, incident response, and production change approval, the toolchain will not save you.
The minimum operating model needs clear accountability across four areas:
- Application teams: Own code quality, service behavior, and release readiness.
- Platform engineering: Own paved-road infrastructure, shared deployment patterns, and runtime standards.
- Security and compliance: Define control requirements, review exceptions, and verify evidence.
- Operations or SRE: Own reliability practices, on-call structure, and recovery procedures.
Some organizations have enough internal depth to build that model themselves. Others use a dedicated development team to stand up the first platform standards while internal leaders retain architectural and compliance ownership. That trade-off can speed execution, but only if the exit path is clear and the knowledge transfer is planned early.
The first toolchain should be coherent and governable. Fancy stacks fail when teams cannot explain how a change moves from pull request to production or how an auditor can trace it afterward.
A practical baseline includes:
- Version control with branch protections: GitHub, GitLab, or a comparable system where every change is reviewable.
- CI/CD platform: A pipeline service your team can secure, standardize, and audit without custom workarounds.
- Infrastructure as code: Terraform or Pulumi for reproducible environments and peer-reviewed infrastructure changes.
- Secrets management: Managed secret storage with rotation, access logging, and short-lived credentials where possible.
- Observability: Logs, metrics, traces, alerting, and ownership mapping tied to the service team.
Standardize early. Letting every product team assemble its own stack usually creates audit gaps, duplicate controls, and incompatible release practices six months later.
Phase two selects the right pilot
The first pilot should carry business value without sitting in the middle of your riskiest clinical dependency chain. Good candidates are bounded services with clear interfaces, moderate traffic, and data flows your security team can map without archaeology.
Strong pilot options often include:
- A patient messaging microservice
- An internal scheduling support service
- A clinical analytics ingestion workflow
- A non-core integration service with clear boundaries
Weak pilot choices usually share the same traits. They are tightly coupled to legacy systems, full of undocumented exceptions, and missing tests that would make change risk visible.
Use the pilot to establish a complete delivery path:
- Source control standards with code review, branch rules, and change traceability.
- Automated build and test that includes dependency, container, and secret scanning.
- Provisioned environments created through IaC only, with no console drift.
- Controlled deployment with rollback steps, approval logic, and release evidence.
- Monitoring and incident ownership defined before the first production push.
Cultural friction usually surfaces here. The technical work is rarely the hard part. Approval bottlenecks, unclear responsibility for production risk, and security reviews that happen only at the end of a release are what slow healthcare teams down.
Phase three measures whether the pilot is safe to repeat
A pilot matters only if another team can follow the same path and get the same result. That requires operating data, not slideware.
Track a small set of metrics that reflect delivery safety and operational discipline:
- Deployment consistency: Releases happen through the same controlled path every time.
- Lead time trend: Approved changes reach production with less waiting and fewer handoffs.
- Recovery performance: Teams can restore service quickly and document what changed.
- Change quality: Releases create fewer avoidable incidents and fewer emergency fixes.
- Control evidence: Audit artifacts, access logs, and approval records are generated as part of delivery, not assembled later.
Healthcare teams should add one more check that generic DevOps guides often skip. Confirm that the pilot’s control evidence is usable by compliance and security reviewers without engineering translating every artifact by hand. If evidence collection depends on tribal knowledge, the model will break at scale.
A strong pilot proves that another team can repeat the pattern under the same security and compliance constraints.
Phase four scales through platform standards
Scale comes from reusable patterns, not from forcing every deployment through a central team. Build platform assets that reduce variation and make the secure path faster than the improvised one.
That usually includes:
- Reusable Terraform modules: Standard network layouts, database patterns, IAM roles, logging baselines, and encryption defaults.
- Shared CI/CD templates: Build, scan, deploy, approval, and rollback stages with secure defaults.
- Golden service patterns: Reference implementations for common healthcare workloads such as APIs, event consumers, and portal backends.
- Policy guardrails: Naming, tagging, retention, access, and secret-handling rules enforced through templates and checks.
- Environment blueprints: Repeatable patterns for dev, test, staging, and production across cloud and on-prem segments.
Hybrid reality matters here. Many healthcare organizations cannot move every workload to one cloud account and call it done. Imaging systems, EHR integrations, legacy identity stores, and regional data constraints often require a mixed estate. The platform model has to account for that from the start, especially for network segmentation, key management, and centralized audit logging.
Leadership also has to decide where centralization helps and where it slows teams down. Too little standardization produces drift. Too much turns the platform group into a ticket queue. The best operating model gives product teams self-service delivery inside clearly enforced boundaries.
Some organizations also examine AI-assisted operations during this stage, especially for alert triage, anomaly detection, or support workflow automation. That work should stay attached to platform outcomes and governance requirements, not run as a separate innovation track.
What usually works and what usually doesn’t
A concise view from practice:
| Approach | What works | What fails |
|---|---|---|
| Team setup | Shared platform standards with product team ownership | One DevOps engineer carrying every team |
| Pilot choice | Bounded service with visible value | Critical legacy monolith as first experiment |
| Security model | Automated checks and policy enforcement in the pipeline | Manual sign-off after build completion |
| Infrastructure | IaC with peer review and drift detection | Console-built environments and undocumented fixes |
| Scaling strategy | Templates, modules, and paved roads | Tool freedom without governance |
Pilot first. Standardize second. Scale only after the controls, evidence, and recovery model work the same way every time.
That order is what turns healthcare DevOps from a tooling exercise into an implementation model that can support patient data systems without trading away compliance, reliability, or delivery speed.
Real-World Examples and Key Learnings
Roughly 80% of healthcare data breaches involve a human element, which is why strong infrastructure and delivery design matter long before an audit or incident response starts. Real examples are useful here only if they show what changed in the operating model, the controls, and the release path.
City of Hope and release acceleration
A widely cited City of Hope transformation story focused on faster releases and better pipeline visibility after the team standardized CI/CD and modernized parts of its delivery stack. The interesting lesson is not the headline improvement. It is the mechanism behind it.
In healthcare environments, release delay usually comes from uncertainty. Teams do not know which dependency will fail, which approval is still pending, or whether a change touched a regulated workflow. End-to-end pipeline visibility reduces that uncertainty. It gives engineering, security, and operations a shared view of build status, test results, deployment history, and rollback state.
Key learning
- Visibility reduces release friction: Faster delivery usually follows once teams can see the full release path, trace failures quickly, and prove what changed.
Clinical analytics platforms and processing at scale
Another healthcare example often referenced in the market describes a clinical analytics platform that improved processing speed after the team moved to containers, automated delivery pipelines, and service-based architecture. That pattern shows up often in health data systems because analytics platforms tend to accumulate operational debt faster than customer-facing apps.
I have seen this firsthand. Early versions of clinical and research platforms often depend on manually scheduled jobs, environment-specific fixes, and fragile deployment steps that only a few engineers understand. That approach can survive while data volumes are low and release frequency is modest. It breaks down once the platform has to handle larger datasets, stricter audit expectations, and hybrid execution across cloud services and retained on-prem systems.
The trade-off is real. Breaking a data platform into smaller services can improve deployability and fault isolation, but it also adds more network paths, more secrets to manage, and more policy enforcement points. In healthcare, that means architecture work has to stay tied to PHI boundaries, access controls, and evidence collection from the start.
Key learning
- Modernization has to serve control as well as scale: Faster analytics matter, but the stronger result is a platform that processes data consistently, deploys predictably, and produces audit evidence as part of normal operation.
Rapid delivery under crisis conditions
Periods of sudden demand, such as telehealth expansion or public health response, expose infrastructure weaknesses fast. Fixed-capacity environments, manual provisioning, and opaque release processes fail first.
The teams that hold up under that pressure usually made a few disciplined choices earlier. They standardized environments with infrastructure as code. They treated observability as an operating requirement rather than a nice-to-have. They defined secure deployment paths before traffic surged. In hybrid healthcare estates, they also knew which services could scale in cloud environments and which had to remain anchored to legacy systems, imaging workflows, or residency constraints.
Key learning
- Resilience is designed before the surge: A hospital or digital health platform cannot invent safe scaling, rollback discipline, and incident visibility in the middle of a demand spike.
New delivery models and compressed timelines
Healthcare leaders often talk about innovation as if the bottleneck sits in product strategy. In practice, infrastructure is usually the limiter. New logistics models, remote care services, patient engagement features, and partner integrations all depend on whether teams can provision environments quickly, enforce policy automatically, and release changes without creating compliance gaps.
That is the healthcare-specific lesson many generic DevOps writeups miss. Faster delivery only matters if the platform can support regulated data flows, mixed cloud and on-prem dependencies, and security review without returning to manual gates for every release.
Key learning
- Platform design shapes business options: Organizations can test new care and operations models faster when their infrastructure already includes reusable controls, deployment standards, and clear ownership boundaries.
For leaders comparing these patterns across their own estate, the useful question is straightforward. Did the team only speed up deployment, or did it also improve traceability, access control, recovery, and compliance evidence in the same workflow? In healthcare DevOps, the second outcome is the one that lasts.
Building Your Future-Ready Healthtech Foundation
Patient data platforms fail in predictable ways. Teams treat compliance as paperwork, keep infrastructure knowledge trapped with a few operators, and postpone security controls until release time. In healthcare, those choices turn routine changes into audit risk, outage risk, and patient trust risk.
A future-ready foundation starts with platform standards that engineers can follow without opening a policy binder for every deploy. Golden paths for provisioning, identity, secrets, logging, and service onboarding reduce variance across teams. That matters in healthtech because every exception creates more review work, more evidence gaps, and more ways PHI can move outside approved boundaries.
The technical baseline is clear. Use infrastructure as code to make environments reproducible. Keep CI/CD pipelines tied to approval policy, test evidence, and change records. Design identity around least privilege and short-lived access, not shared admin habits. Treat observability as an operational control, not a dashboard project, because audit investigations and production incidents often depend on the same logs, traces, and immutable records.
Hybrid reality also needs to be designed in, not worked around later. Many healthcare estates will keep some systems on-prem for years because of EHR integrations, device dependencies, data residency requirements, or procurement cycles. The right target architecture usually mixes cloud-native services with controlled private network paths, segmented workloads, and explicit trust boundaries between modern applications and legacy clinical systems.
This is also where leadership discipline shows up. Teams need clear service ownership, defined recovery objectives, and a release model that matches clinical risk. A patient messaging service, a billing integration, and an internal analytics job should not all carry the same deployment rules. Good platform engineering reflects those differences while keeping the control model consistent.
The payoff is practical. Faster releases matter, but the bigger gain is repeatability under pressure. Teams can ship changes, pass reviews, recover from incidents, and produce evidence without rebuilding the process each time.
If you are investing in healthcare DevOps and infrastructure engineering, choose operating models and partners that can handle both regulated delivery and long-tail modernization. The architecture only lasts if the team can support HIPAA and HITRUST control mapping, hybrid infrastructure constraints, and the day-two work of running patient data systems safely at scale.
Frequently Asked Questions
How does DevOps protect PHI better than traditional release processes
Healthcare breaches rarely come from one dramatic failure. They usually start with routine exceptions. A copied production database for testing, a hardcoded credential in a deployment script, or verbose application logs that capture patient identifiers.
DevOps reduces that exposure by turning security controls into repeatable system behavior. Lower environments should use masked or synthetic data. Secrets should come from a managed store with rotation and access policies. Pipelines should enforce encryption settings, policy checks, approval gates, and deployment records before a change reaches production.
Infrastructure as code matters here for a practical reason. Teams can inspect the actual configuration under version control, review who changed it, and prove that the deployed environment matches the approved baseline. In regulated healthcare systems, that traceability matters as much as the technical control itself.
The main advantage is consistency. Manual release steps depend on memory and local habits. Automated controls run the same way every time.
What cultural change is hardest in healthcare DevOps
Shared ownership is usually the hardest shift.
Healthcare organizations often inherit a model where development builds, operations deploys, security reviews, and compliance documents after the fact. That structure feels familiar, but it creates queues, weak handoffs, and long feedback loops. It also makes incident response harder because each team only sees part of the release path.
A better model gives one delivery team visibility from commit through runtime, with security and compliance built into that workflow instead of attached at the end. That does not mean every developer needs to become a platform specialist or auditor. It means the team shipping a patient-facing service understands the deployment path, the recovery objective, the data handling rules, and the evidence produced along the way.
The friction usually shows up in a few predictable places:
- Approval habits: Manual checkpoints feel safer, even when they are inconsistent and poorly documented.
- Role boundaries: Teams may resist being accountable for uptime, rollback quality, or post-release validation.
- Tool sprawl: Separate workflows across engineering, security, and IT make release evidence harder to collect and trust.
- Legacy outage memory: Staff who have lived through clinical system failures often treat any release automation as added risk.
Leadership has to set the expectation clearly. Automation does not reduce control. It makes control testable, auditable, and repeatable.
Where does AI fit into healthcare DevOps
AI is most useful when applied to narrow operational problems with clear owners. In healthcare DevOps, that usually means anomaly detection across logs and metrics, alert clustering during incidents, noisy signal reduction, test selection, configuration review, and support for security triage.
It should not sit in the decision path for sensitive changes without oversight. For example, using AI to summarize an incident timeline is low risk and saves time. Using AI to approve firewall changes or classify PHI exposure without a human review step creates governance problems fast. In regulated systems, every AI use case needs scope, validation, and an audit trail.
The right starting point is boring on purpose. Pick one pain point with measurable impact, such as reducing false-positive alerts for an on-call team or improving incident correlation across a hybrid estate. Prove that it works. Then extend from there.
If you are evaluating partners for this kind of work, look for teams that can connect platform automation, cloud operations, and healthcare compliance controls in one operating model. General AI capability is not enough. The implementation has to fit HIPAA, HITRUST, and the existing patient data systems that still span cloud and on-prem environments.
If you're looking for a practical partner to modernize regulated platforms, strengthen delivery workflows, and build compliant cloud foundations, Bridge Global brings experience in healthtech engineering, AI-enabled delivery, and secure modernization. Their work across cyber compliance solutions and product engineering can help teams move from pilot improvements to a durable operating model.
About Upendra Jith
Upendrajith completed his Master's in English and has been a commercial content developer for the past three years. He's more inclined to develop content with a 'street-smart' delivery on topics such as technology, media, or anything he can get his hands on. He has a fixation on lyrics, dark poetry, media, technology, and flow arts.
View all posts by Upendra Jith →