


Healthcare Data Privacy Software Development: A Guide
Healthcare software teams don't get to treat privacy as a backlog item anymore. The average cost of a healthcare data breach reached $10 million in 2024, the highest of any industry, and hacking incidents rose 239% since 2018, with ransomware driving 79.7% of breached patient records in 2023 according to HIPAA breach statistics.
That changes how healthcare data privacy software development should be approached. Privacy isn't just a legal review before launch. It shapes data models, API boundaries, cloud architecture, test environments, model training pipelines, vendor selection, and incident response.
Teams that build trustworthy health products usually make one shift early. They stop asking, "How do we make this compliant at the end?" and start asking, "What would this system look like if privacy were part of the architecture from day one?" That's the difference between patching controls onto a risky product and engineering a system that can survive audits, integrations, AI expansion, and operational scale.
A capable healthtech software development partner can help make that shift practical, especially when product teams need to balance release speed, interoperability, and regulated data handling at the same time.
The High Stakes of Privacy in Modern Healthcare Software
Healthcare systems carry a uniquely difficult mix of risk. They hold highly personal data, support time-sensitive care, connect to third-party systems, and increasingly rely on cloud services, mobile apps, remote monitoring, and AI-assisted workflows. A flaw in any one layer can expose data far beyond the original application boundary.
The cost of failure isn't limited to fines or incident response. Product teams lose implementation momentum. Security teams get pulled into containment. Clinical stakeholders lose confidence in the software. Procurement slows down future rollouts because trust has been damaged.
Why privacy has become a product architecture issue
In older delivery models, privacy was often treated as a compliance workstream owned by legal, security, or governance. That no longer holds up. Modern healthcare platforms exchange data across patient portals, EHR integrations, analytics pipelines, AI tooling, billing vendors, and partner APIs. Every one of those touchpoints creates design decisions that developers own.
A practical healthcare privacy architecture has to answer questions like these:
- What data is necessary for the user journey, the clinical workflow, or the model feature set?
- Which services should ever see raw PHI and which should only receive pseudonymized or tokenized values?
- Where does consent live and how is it enforced across downstream systems?
- How do logs, traces, and error events behave when something goes wrong in production?
- Can developers test safely without exposing real patient records?
Practical rule: If a team can't draw the path of PHI through the system, it probably doesn't control privacy well enough.
What disciplined teams do differently
Strong teams build privacy controls into delivery rituals, not just infrastructure. They add privacy checks to backlog refinement, threat modeling to technical design, secret scanning to CI, data retention rules to schema design, and auditability to release criteria.
That sounds heavy, but it usually reduces rework. Systems built with clear privacy boundaries are easier to reason about, easier to test, and easier to defend during customer security reviews.
Navigating the Regulatory Maze HIPAA GDPR and Beyond
Development teams do not struggle due to unfamiliarity with HIPAA or GDPR. They struggle because the legal language doesn't automatically translate into software behavior. Developers need implementation rules, not abstract obligations.
The demand for that translation is one reason the healthcare privacy tooling market keeps expanding. The Privacy Management Software in Healthcare Market was valued at USD 487.3 million in 2024 and is projected to reach USD 1.1 billion by 2030, growing at a 14.1% CAGR, driven by automated compliance needs around regulations such as HIPAA and GDPR, according to Research and Markets coverage of the healthcare privacy management software market.

HIPAA in developer terms
HIPAA affects architecture far more than many teams expect. The common mistake is to reduce it to encryption and access control. Those matter, but they aren't enough.
For engineers, HIPAA usually translates into a few hard requirements:
- Minimum necessary access means APIs shouldn't return entire patient objects when a workflow needs only demographics or scheduling data.
- Auditability means every sensitive action should produce a useful, reviewable log event without leaking PHI into logs.
- Integrity and confidentiality mean transport security, secrets handling, key management, and secure defaults need to be standard.
- Business associate exposure means vendor due diligence matters if cloud tools, analytics tools, support tooling, or AI tools can touch protected data.
A patient messaging module is a good example. If the notification service receives full clinical payloads when it only needs a template token and destination metadata, the system is already violating the spirit of minimum necessary design.
GDPR changes the shape of data workflows
Teams handling EU patient data need to think beyond security and into rights management. GDPR pushes software teams to support data subject access requests, deletion workflows where legally appropriate, purpose limitation, consent tracking, and data minimization across the full lifecycle.
That changes implementation details:
- Consent can't be a static checkbox buried in onboarding. It needs versioning, timestamps, policy references, and downstream enforcement.
- Data export flows need structure so teams can respond to access requests without manual database archaeology.
- Deletion and retention policies need orchestration across app databases, object storage, backups, and integrated systems.
For teams working on secure document exchange, this practical guide to HIPAA compliant document sharing is useful because document workflows often become the first place where privacy promises fail in practice.
HITECH, regional rules, and operational reality
HITECH raised the operational stakes around breach response and electronic health data handling. In practice, that means teams need better visibility, faster detection, cleaner audit trails, and deployment discipline that supports post-incident forensics.
Global products face a harder problem. HIPAA may define one set of expectations, while GDPR, CCPA, or POPIA influence consent, deletion, disclosure, or cross-border processing decisions differently. The answer isn't to overbuild one universal workflow. It's to create policy-aware services and configurable controls.
A compliant product usually has fewer hidden assumptions. That's why regulated architecture often becomes more maintainable architecture.
If you need a deeper engineering view, Bridge Global's HIPAA compliant application development guide is relevant for teams mapping legal obligations into application design choices.
Automated cyber compliance solutions become more useful as systems grow because manual evidence gathering doesn't scale across cloud environments, AI services, and partner integrations.
Implementing Privacy by Design in Your SDLC
Privacy by Design works when it changes delivery behavior. It fails when teams frame it as a policy statement. In healthcare data privacy software development, the gap usually appears in familiar places: teams don't apply the minimum necessary principle to AI models, privacy impact assessments for offshore or distributed delivery are weak, and cloud or AI integrations go live without proper audit coverage, as outlined in Censinet's discussion of HIPAA compliance in clinical software development.
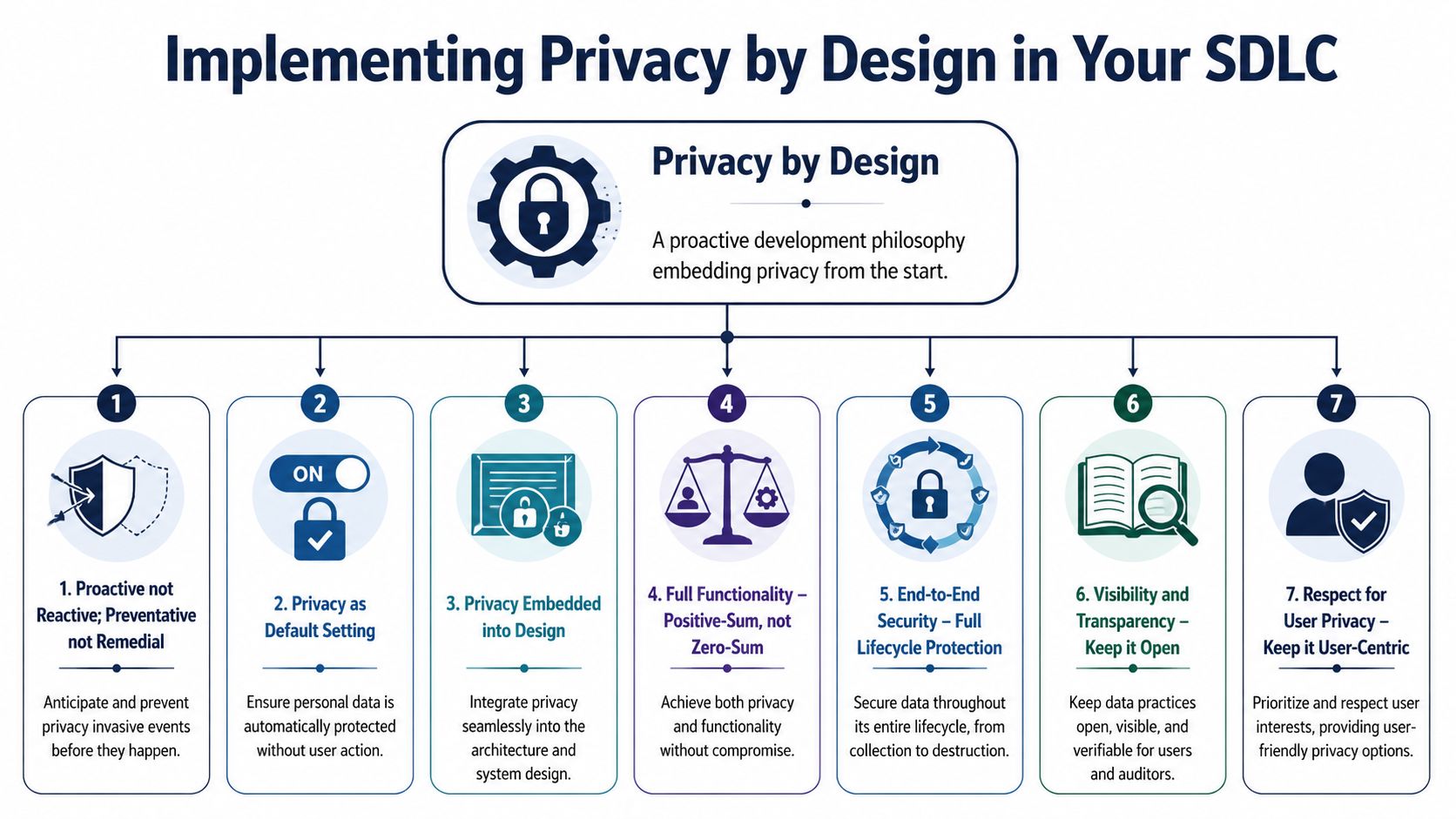
The seven principles only matter if they show up in delivery
The original seven principles are still useful, but teams need to operationalize them:
Proactive, not reactive
Run privacy impact assessments before architecture is finalized. Do threat modeling before sprint delivery, not after pen testing.Privacy as the default
Start with the most restrictive sharing settings, shortest feasible retention behavior, and least permissive role access.Privacy embedded into design
Put privacy constraints in service contracts, schema design, event payloads, and infrastructure templates.Positive-sum, not zero-sum
Don't accept the false trade-off that useful clinical software must expose more data than necessary.End-to-end lifecycle protection
Secure data from collection through archival and destruction, including exports, support tooling, and backups.Visibility and transparency
Make consent logic, access events, and policy enforcement reviewable by auditors and understandable to users.Respect for user privacy
Give patients and administrators controls they can use, not legal language disguised as UX.
What this looks like inside a real SDLC
Most privacy failures happen at handoffs. Product defines a broad requirement. Engineering implements the fastest path. Security reviews late. Operations inherit the complexity.
A better pattern is to make privacy a delivery artifact at each phase:
Discovery phase
Identify regulated data types, lawful uses, retention requirements, integration dependencies, and cross-border data exposure before scope is approved.Design phase
Define trust boundaries, role models, consent architecture, encryption strategy, and de-identification approach.Build phase
Enforce secure coding standards, validate authorization at the service layer, scan dependencies, and block PHI in logs and telemetry.Test phase
Use de-identified or synthetic datasets. Test revocation, retention expiry, DSAR handling, and audit-log completeness.Release and operations
Monitor access anomalies, validate vendor changes, rotate secrets, and rehearse breach response.
Design check: Every user story that touches PHI should have a privacy acceptance criterion, not just a functional one.
The cultural shift teams often resist
Privacy by Design forces teams to admit that convenience creates exposure. Engineers want broad admin access because it speeds debugging. Product owners want verbose analytics because it improves decision-making. Data teams want raw datasets because feature engineering is easier.
Those instincts are understandable. They also create unnecessary risk.
The healthiest pattern is controlled friction. Teams should have to justify why raw data is needed, why a role needs broader visibility, or why an AI workflow can't rely on de-identified features. That doesn't slow serious work. It removes lazy defaults.
Mature product engineering services and disciplined custom healthcare software development practices hold significant importance. The process has to support privacy decisions repeatedly, not just once.
For teams formalizing controls across release pipelines, our guide to the secure software development lifecycle is a useful companion because SSDLC controls are where Privacy by Design becomes enforceable.
Secure Architecture Patterns for HealthTech Platforms
A secure healthcare platform isn't one pattern. It's a stack of patterns working together. Good architecture limits blast radius, keeps data exposure narrow, and makes mistakes easier to contain.

Encrypt the right things in the right places
Encryption at rest is table stakes for databases, object storage, backups, and queues that may contain PHI. Transport encryption should cover browser-to-app, service-to-service, and integration traffic. For telehealth or messaging, teams should also think carefully about end-to-end encryption, especially when highly sensitive discussions or attachments move between users.
The trade-off is operational visibility. End-to-end encryption improves confidentiality, but it can make moderation, support, indexing, and certain analytics harder. Teams need to design for those constraints rather than bypass them with insecure backdoors.
Tokenize, pseudonymize, or anonymize based on actual use
These terms get mixed together constantly, and that leads to poor design.
| Approach | What it does | Best use case | Main limitation |
|---|---|---|---|
| Tokenization | Replaces a sensitive value with a surrogate token | Payment fields, identifiers, workflow references | Requires secure token vault design |
| Pseudonymization | Replaces direct identifiers while keeping data linkable under control | Analytics, research workflows, internal processing separation | Re-identification risk still exists |
| Anonymization | Removes or transforms identifiers so individuals shouldn't be identifiable | Population-level reporting, low-risk secondary use | Utility often drops sharply |
If engineers need to reconnect data to a patient later, anonymization usually isn't the right tool. If operations never need the original value in a given service, tokenization is often cleaner than distributing raw identifiers across microservices.
Build access control around context, not job titles alone
Basic role-based access control works for many admin workflows, but healthcare often needs more context. A nurse may have the role to view patient records, but should only access patients assigned to a ward, a shift, or a treatment relationship. That's where attribute-based access control becomes useful.
A practical split looks like this:
- Use RBAC for broad baseline permissions such as clinician, billing admin, support agent, or patient.
- Use ABAC for context constraints such as location, care team membership, encounter status, facility, or emergency override.
- Use service-layer authorization instead of trusting frontend rules. Browsers don't enforce compliance. Backend services do.
The safest architecture assumes that users will make mistakes and that integrations will eventually behave in unexpected ways.
Isolate services that handle raw PHI
Not every service should process full patient records. Limit raw PHI to the smallest number of systems possible. Search indexes, reporting layers, notification services, and feature flag systems often receive more sensitive data than they need because nobody challenged the integration contract.
Use segmentation deliberately:
- PHI core services handle direct patient data under strict controls.
- Derived data services consume only the fields they need.
- Analytics pipelines use de-identified or pseudonymized data whenever possible.
- Support tooling should expose controlled views, not production databases.
These choices belong inside custom software development, not as a retrofit after architecture review.
A Practical Guide to Data Lifecycle Management
A single patient address can tell you a lot about a system's privacy posture. It might enter through registration, move into an EHR sync, appear in billing, be copied into support tickets, land in an analytics export, and linger in backups long after it stopped serving any clinical or operational purpose. That journey is where many privacy failures happen.
Collection and consent
Start at intake. If a form asks for data because it "might be useful later," the system is already drifting away from defensible collection. Good forms ask only for data that supports a defined workflow, care process, or legal obligation.
Consent needs the same discipline. A healthcare app may need one permission for care delivery communications, another for research participation, and another for optional engagement features. Storing all of that as a single boolean flag guarantees trouble later when a user withdraws one purpose but not the others.
Use, testing, and storage
Once data is in the platform, teams should control how it spreads. Developers often focus on production databases, but privacy exposure frequently appears in lower environments, exported spreadsheets, log files, and ad hoc support snapshots.
That means a sound process should include:
- De-identified or synthetic test data instead of production copies for QA and development.
- Purpose-bound storage so systems don't become generic catch-alls for PHI.
- Controlled support access with approval workflows and session logging.
- Retention labels attached to data categories, not buried in policy documents.
This matters even more with distributed delivery models or a dedicated development team, where access boundaries and environment hygiene need to hold across locations and roles.
A retention policy that no system enforces isn't a policy. It's a wish.
Retention and deletion
Deletion in healthcare is more complex than pressing a purge button. Some records must be retained for legal, contractual, or clinical reasons. Others should be removed once their purpose ends. The challenge is to make those distinctions executable inside the platform.
A useful operating pattern is to classify data by retention rule, apply lifecycle metadata at creation time, and automate disposition where possible. Teams designing those workflows may find this overview of data deletion practices helpful as a practical reference for how deletion policies translate into actual operational controls.
The final test is traceability. For any data category, the team should be able to answer four questions quickly: why it was collected, where it is stored, who can access it, and when it should be deleted or archived.
Mitigating Unique Privacy Risks in Healthcare AI
AI systems create privacy exposure in places many healthcare teams do not inspect. The PMC review of privacy technologies in healthcare AI highlights a recurring problem: techniques such as federated learning and blockchain reduce some risks, but they do not stop inference attacks by themselves. In practice, healthcare data privacy software development for AI needs a threat model that covers training data, prompts, model artifacts, embeddings, and vendor tooling.
The difference matters at build time. A web application can pass a conventional security review and still expose patient information through model outputs, retained prompts, or vector search results. I see this most often when teams bolt AI features onto an existing platform without redefining trust boundaries around the model pipeline.
Where AI creates new privacy exposure
Training pipelines concentrate data that used to stay separate. Clinical notes, claims data, device telemetry, scheduling history, and behavioral signals often end up in one feature store or notebook workflow. That concentration improves model performance. It also raises the blast radius of a mistake.
The common failure points are specific:
- Model inversion. An attacker uses outputs to reconstruct sensitive attributes from training data.
- Membership inference. An attacker estimates whether a particular patient record was included in the training set.
- Prompt leakage. Staff or users paste PHI into chat interfaces, copilots, or third-party model endpoints that were never approved for regulated data.
- Embedding exposure. Vector representations can preserve identifiable clinical context even after obvious identifiers are removed.
- Pipeline sprawl. Temporary datasets, notebooks, caches, fine-tuned checkpoints, and evaluation artifacts sit outside the controls applied to the main product.
Large language model workflows add another problem. Prompts, retrieved context, tool calls, and generated responses each create a separate disclosure path. Teams building these systems should treat responsible AI governance for healthcare software as an engineering concern, not a policy attachment.
Privacy-enhancing technologies help, but each one has limits
Teams usually ask which privacy technology to choose. The better question is which failure mode needs to be reduced, and what accuracy, latency, and operating cost the product can tolerate.
| Technology | What It Does | Useful In | Trade-off |
|---|---|---|---|
| Federated learning | Trains models locally and shares updates instead of raw records | Multi-organization collaboration with data locality constraints | Orchestration is harder, and model updates can still leak information |
| Differential privacy | Adds controlled noise to reduce what can be learned about individuals | Analytics, aggregate learning, protected model updates | Poor calibration can damage utility fast |
| Homomorphic encryption | Supports computation on encrypted data in limited scenarios | High-sensitivity workloads where plaintext exposure is unacceptable | High compute cost and implementation complexity |
| Secure enclaves | Runs code inside an isolated hardware-backed execution boundary | Sensitive inference and limited trusted compute environments | Platform dependency and operational overhead |
| Blockchain | Preserves tamper-evident records for events and transactions | Consent provenance and shared audit records in narrow use cases | It does not keep off-chain health data secret |
Federated learning is a good fit for hospital networks that cannot centralize raw records. It is not enough on its own. If gradients or parameter updates are exposed, patient-level patterns can still leak. Differential privacy can reduce that risk, but the privacy budget has to be set deliberately, tested against attack scenarios, and reviewed alongside model utility targets.
Blockchain gets overprescribed in healthcare AI discussions. It can support provenance and consent history. It does not replace access control, key management, or disciplined handling of the underlying datasets.
What holds up in production
The teams that handle AI privacy well usually make five design choices early.
Reduce the training surface area
Use only the fields needed for the model task. Extra attributes increase re-identification risk and usually create more cleanup work later.De-identify before experimentation spreads copies
Strip direct identifiers and tokenize linkable fields in the first preprocessing step, before data reaches notebooks, feature engineering jobs, or annotation queues.Put LLM traffic behind a controlled gateway
Redact PHI where possible, enforce approved model endpoints, restrict tool invocation, and log prompt events without storing raw sensitive content unless there is a documented reason.Treat model artifacts as regulated assets
Checkpoints, embeddings, evaluation sets, cached responses, and fine-tuning files need retention, access control, and deletion rules. Many teams secure the source tables and forget the artifacts created from them.Review AI vendors as data processors, not just software vendors
Inference providers, annotation firms, observability tools, and managed vector databases all affect privacy posture and breach scope.
Bridge Global is one provider that states it applies Privacy by Design, de-identification controls, and secure API patterns in healthcare AI delivery through its AI development services and AI transformation framework.
The trade-off is technical, not theoretical
Healthcare AI teams balance three forces: privacy protection, model usefulness, and delivery speed. Stronger privacy controls can reduce signal. More telemetry can help debug hallucinations and drift, but it can also capture sensitive context. External AI services shorten build time, yet they expand the vendor risk surface and complicate cross-border processing analysis.
Good teams make those trade-offs explicit. They test whether a privacy control effectively reduces attack exposure, measure what it costs in accuracy or latency, and document why that choice fits the clinical or operational use case. That is what Privacy by Design looks like in AI systems. It is not a statement in a policy deck. It is architecture, pipeline controls, and verification work built into the product from the first model experiment.
Your Actionable Implementation Checklist
Privacy programs fail in delivery when ownership is vague and controls arrive after the architecture is set. The teams that stay out of trouble make privacy requirements testable, assign them to named roles, and review them at the same cadence as security and reliability work.
Use this checklist as a release gate, not a policy appendix.
Strategy and discovery
- Map regulated data before scope is fixed. Identify PHI, consent-restricted data, external sharing points, derived data sets, and any flow that could trigger cross-border review.
- Assign decision owners early. Product should own data purpose, engineering should own control implementation, security should own verification, compliance should own interpretation, and operations should own runtime procedures.
- Review vendors before they become dependencies. That includes cloud services, analytics tools, AI providers, support platforms, and integration partners.
- Set an AI data use policy at project start. Define whether prompts, fine-tuning sets, embeddings, transcripts, and model outputs can contain patient data, and who approves exceptions.
Design and architecture
- Turn Privacy by Design into architecture artifacts. Add data classification, trust boundaries, retention rules, deletion triggers, and access models to design reviews.
- Choose controls based on the workflow. Tokenization helps when identifiers must be restored later. Pseudonymization helps analytics. Field-level encryption adds protection but increases key management and debugging overhead.
- Design for operational rights handling. Consent changes, access requests, corrections, legal holds, and audit exports should be supported by system behavior, not manual spreadsheet work.
- Separate AI components from core clinical systems. Isolate prompt handling, model gateways, vector stores, and artifact storage so a single failure does not expose the full patient context.
Development and testing
- Write privacy acceptance criteria into user stories for features that collect, transform, store, or expose health data.
- Block PHI from logs, traces, prompts, and analytics events before code reaches production.
- Use de-identified or synthetic test data by default. Production snapshots create cleanup, access, and retention problems that usually outlast the sprint they were copied for.
- Add privacy checks to CI/CD. Scan infrastructure changes, API schemas, logging configs, and data store permissions for policy violations.
- Test AI paths separately from standard app flows. Prompt injection, retrieval leakage, unsafe output storage, and model artifact exposure require their own review criteria.
Operations and improvement
- Monitor access patterns and data movement, especially bulk export behavior, unusual service-to-service calls, and changes in AI vendor configuration.
- Run breach response exercises with engineering, security, legal, compliance, and operations. Include scenarios involving model outputs, cached prompts, and third-party processors.
- Re-audit integrations on a schedule. Privacy posture changes when vendors add features, move hosting regions, or change subprocessors.
- Bring in targeted outside support when internal capacity is thin through architecture review, privacy engineering assessment, or regulated delivery support.
Strong privacy programs reduce avoidable engineering work. Clear data boundaries cut rework. Good audit trails shorten enterprise reviews. Controlled AI pipelines let teams experiment without creating a hidden retention and leakage problem.
Bridge Global's client cases show how regulated delivery models and product engineering are applied in practice.
Frequently Asked Questions
Is encryption enough to make healthcare software compliant
No. Encryption protects data in storage and transit, but compliance also depends on access control, auditability, consent handling, retention, secure development practices, and vendor governance. Many privacy failures happen because too many systems or people can still access decrypted data.
What's the biggest mistake teams make in healthcare data privacy software development
They collect or expose more data than the workflow needs. Overbroad APIs, verbose logs, copied production data in test environments, and loosely governed AI tooling are common examples. Most privacy incidents start with unnecessary exposure, not exotic attack techniques.
How should offshore or distributed teams work safely with healthcare data
They should work inside clearly segmented environments, use least-privilege access, rely on de-identified or synthetic data for most delivery tasks, and follow documented approval and audit procedures for any sensitive access. The key issue isn't team location. It's whether the operating model enforces privacy consistently.
Can AI be used safely with patient data
Yes, but only with stricter controls than many teams apply today. Teams need data minimization, vendor review, prompt controls, artifact governance, and technical mitigations for model leakage risk. AI projects should have privacy review criteria separate from standard app security checks.
When should a team run a privacy impact assessment
Before final architecture decisions are made and again when the system changes materially. A PIA is most useful when it informs design choices early, vendor selection, data flow boundaries, and deployment rules. Running it after development is mostly documentation, not risk reduction.
If you're planning a regulated platform, modernizing an existing health product, or introducing AI into clinical or operational workflows, Bridge Global can support the engineering side of that effort with practical delivery across compliance, architecture, and product development.
About Stephanie Cornelissen
Stephanie Cornelissen is a Technical Solutions Consultant with strong experience helping organizations navigate complex digital change. She works closely with teams to align business goals with practical, scalable technology solutions. With expertise in system architecture, integrations, and emerging technologies, she focuses on solving real-world problems through thoughtful execution. She enjoys working where technology meets business strategy and measurable growth.
View all posts by Stephanie Cornelissen →