


An Essential Guide to Healthcare Data Engineering
At its core, healthcare data engineering is all about building the digital plumbing that collects, stores, and reliably moves massive amounts of health information. It takes all the fragmented data from countless sources, think electronic medical records (EMRs), lab results, pharmacy systems, and even patient wearables, and turns it into a clean, unified, and accessible resource. This is the raw material that clinicians, data analysts, and AI models need to do their work.
What Is Healthcare Data Engineering and Why Is It So Critical?
Picture a busy hospital. You see the doctors, nurses, and specialists working with patients. But what you don’t see is the hidden infrastructure that makes it all run: the power, the water, the communication systems. Healthcare data engineering is that hidden infrastructure, but for medical information. It’s the technical backbone ensuring the right data gets to the right people and systems, securely and on time.
This is much more than just digital filing. The real mission is to create a single source of truth from dozens of disconnected systems. Without it, critical insights stay locked away in data silos, making it nearly impossible to perform advanced analytics, coordinate care across departments, or even get a complete picture of a single patient’s journey.
The Core Mission of a Healthcare Data Engineer
A healthcare data engineer is the architect and mechanic of these digital pipelines. Their work is the unsung hero behind almost every modern medical innovation, from AI-powered diagnostic tools to systems that make hospitals run more efficiently.
Their day-to-day responsibilities boil down to a few key areas:
-
Data Ingestion: Pulling in data from a huge variety of sources. This could be structured data from an EMR, billing codes from an administrative system, medical images (like DICOM files), or real-time streams from IoT sensors.
-
Data Transformation: Taking that raw, often messy, data and making it usable. This involves cleaning up errors, standardizing medical codes (like LOINC or SNOMED), and often de-identifying sensitive information to protect patient privacy.
-
Data Storage & Access: Designing and building the secure, scalable data warehouses or data lakes where all this cleaned-up data lives. This is where analysts, researchers, and applications can go to get the information they need.
The ultimate goal is to power data-driven medicine. By building a reliable data foundation, engineers enable healthcare providers to spot public health trends, predict patient outcomes, and personalize treatments like never before.
The importance of this foundational work is skyrocketing as the industry pushes deeper into complex analytics and AI. As a premier AI solutions partner, we see it every day: solid data engineering isn’t just a nice-to-have, it’s the absolute prerequisite for success. It’s what makes advanced healthcare software development possible. By turning chaotic data streams into organized, ML-ready assets, data engineering is directly building the future of patient care.
2. Choosing the Right Blueprint for Your Data Platform
Picking the right architecture for a healthcare data platform is a lot like deciding on the foundation for a new hospital. A weak or ill-suited foundation will limit everything you build on top of it, creating instability and hampering future growth. But a strong, modern one can support complex, life-saving operations for decades.
In healthcare data engineering, this foundation is all about how you move, store, and prepare data for analysis. The choices you make here will determine how quickly you can get answers and how much value you can extract from your data.
The Old Guard: ETL
For years, the standard approach was ETL (Extract, Transform, Load). It was a straightforward, sequential process:
-
Extract data from a source system.
-
Transform it into a clean, predefined, structured format.
-
Load it into a central data warehouse.
This method is orderly and predictable, but its greatest strength is also its biggest weakness. You have to decide on the data’s final structure before you load it. That rigidity is a huge problem in healthcare, where new research questions and analytical needs pop up all the time. You might end up discarding raw data during that initial transformation step, only to realize later that it held the key to a critical insight.
The Modern Playbook: ELT and Real-Time Streaming
Today, the smart money is on ELT (Extract, Load, Transform), which flips the classic process on its head. Raw, unfiltered data from EMRs, lab systems, IoT devices, you name it, is extracted and loaded directly into a central repository, often a data lake.
The transformation happens much later, on an as-needed basis, when someone actually has a question to answer. This “load first, transform later” model is a game-changer for healthcare. The future value of raw data, like genomic sequences or unstructured physician notes, is often unknown at the time of collection. ELT preserves that potential.
This entire journey, from messy source data to life-saving insights, is powered by engineering.
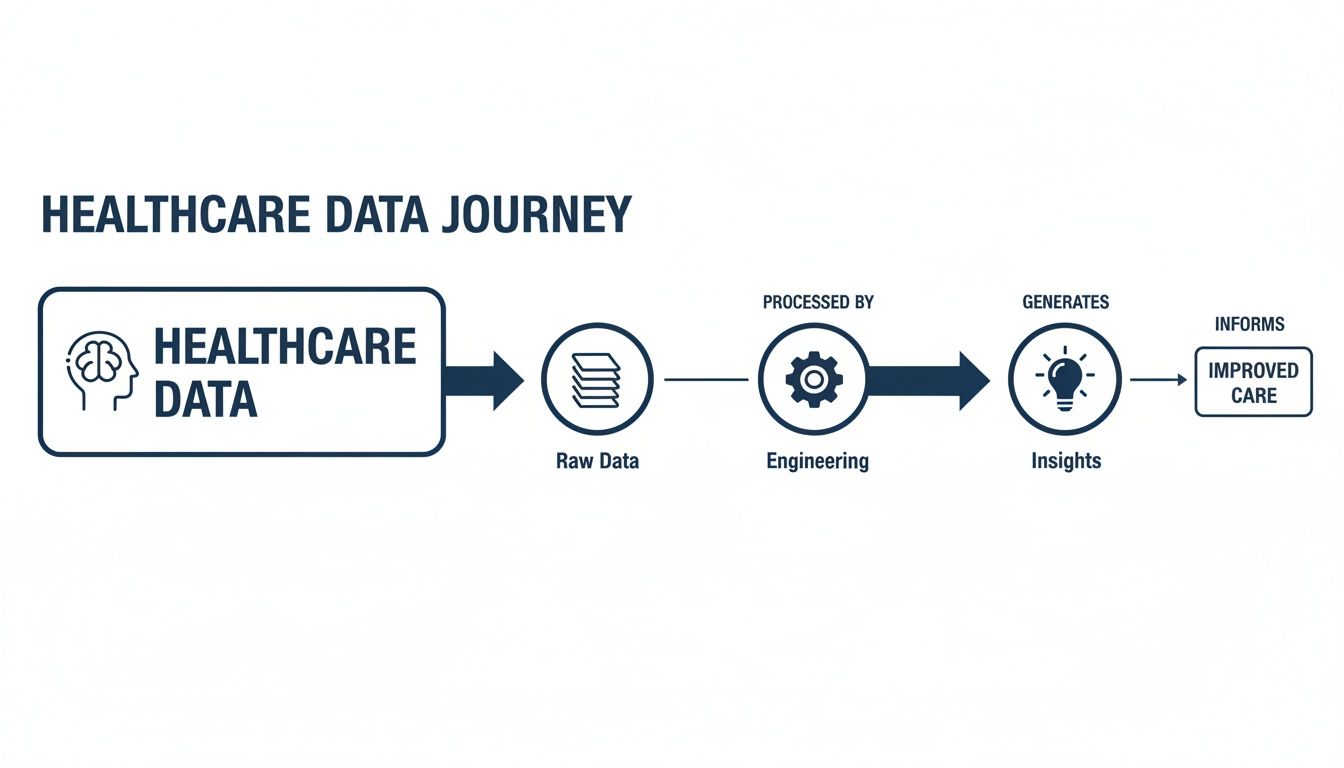
As you can see, engineering is the critical bridge. It’s what turns the chaotic flood of raw information into the clean, reliable fuel needed to improve patient outcomes.
But healthcare doesn’t always move in batches. We increasingly need data now. This is where streaming architectures come in. Using technologies like Apache Kafka, data flows continuously from sources like ICU monitors or wearable sensors. This enables immediate analysis and alerts, powering real-time applications that can predict patient deterioration or manage hospital bed capacity on the fly.
Data Lake vs. Data Warehouse vs. Data Mesh
Choosing the right blueprint means understanding the fundamental storage and management patterns. Each one serves a distinct purpose, and they often work together.
A data lake is like a vast reservoir. It’s designed to hold massive amounts of raw, unstructured data in its native format. This is the playground for data scientists and researchers who need access to unfiltered information for deep exploratory analysis and training machine learning models.
A data warehouse, on the other hand, is a finely curated library. It contains highly structured, filtered, and processed data that has been optimized for specific business intelligence and reporting tasks. Clinicians and hospital administrators use this to build dashboards on patient outcomes, track key performance indicators, or monitor operational efficiency.
The Data Mesh is a newer, more decentralized concept gaining traction in large, complex healthcare systems. Instead of one central data team trying to manage everything, a data mesh empowers individual domains (like cardiology, radiology, or finance) to own and manage their own data as a “product.” This model prevents the bottlenecks common in centralized systems and promotes greater agility and scalability.
So, how do you choose? Here’s a high-level comparison to help guide your thinking.
Comparing Healthcare Data Platform Architectures
| Architecture | Ideal Use Case | Data State | Core Benefit |
|---|---|---|---|
| Data Lake | Storing vast, diverse raw data for machine learning, research, and exploratory analysis. | Raw, unstructured, semi-structured | Flexibility. Preserves all data in its original format for future, unknown uses. |
| Data Warehouse | Powering business intelligence, clinical dashboards, and standardized operational reporting. | Structured, filtered, processed | Performance. Optimized for fast and reliable queries on clean, aggregated data. |
| Data Mesh | Large, decentralized organizations needing to scale data ownership and avoid central bottlenecks. | Both raw and structured | Agility. Empowers domain teams to deliver data products faster and more effectively. |
It’s important to remember that these architectures are not mutually exclusive.
In fact, the most effective modern healthcare data platforms are often hybrids. They combine a data lake for raw data storage and discovery, a data warehouse for structured reporting, and streaming pipelines to handle real-time needs.
Building a platform that elegantly combines these elements requires deep, hands-on experience. As a seasoned AI solutions partner, we specialize in designing and implementing these complex blueprints. Our expertise in custom software development ensures the architecture we build aligns perfectly with your clinical and operational goals, creating a rock-solid foundation for everything from advanced analytics to groundbreaking AI applications.
Navigating Security and Compliance in Healthcare Data
When we talk about healthcare data engineering, security isn’t just a feature on a list; it’s the absolute foundation. In other fields, a data breach is a problem. It might lead to financial loss or a hit to the company’s reputation. But in healthcare, a security failure can have profound, life-altering consequences for real people.
That’s why robust security and compliance can’t be bolted on at the end. They must be woven into the very fabric of the data architecture from day one.

This goes far deeper than a simple compliance checklist. It’s about translating dense legal frameworks like the Health Insurance Portability and Accountability Act (HIPAA) into concrete, day-to-day engineering decisions. For data engineers, this means designing systems that are secure by default. It’s a specialized skill set that requires a deep understanding of the entire regulatory landscape.
Turning HIPAA Principles into Engineering Reality
At its heart, HIPAA is all about safeguarding Protected Health Information (PHI). For a data engineer, this isn’t an abstract legal concept; it’s a set of technical requirements that dictate how data is stored, moved, and accessed.
-
Robust Access Controls: This is so much more than just a login and password. Engineers have to implement strict Role-Based Access Control (RBAC). Think about it: a clinician should only be able to see the records for patients directly in their care, not the entire hospital’s database. This “principle of least privilege” is a core engineering task, built into databases, applications, and APIs.
-
Comprehensive Audit Trails: Every single time PHI is touched, it must be logged. This means creating an immutable, timestamped record of who accessed what data, when they did it, and from where. These logs aren’t just for pulling reports to satisfy an auditor; they are a vital, real-time tool for spotting and responding to potential security threats.
Compliance is an ongoing engineering challenge, not a one-time setup. A secure data platform must constantly evolve to counter new threats while adapting to changes in privacy regulations.
Key Technologies for Protecting Patient Data
To build these secure systems, engineers lean on a specific toolkit of technologies and methods designed to shield sensitive information. These aren’t just nice-to-haves; they’re essential components of any modern healthcare data pipeline.
Encryption End-to-End
Data has to be locked down at every point in its journey. This really boils down to two critical states:
-
Encryption in Transit: Using protocols like TLS 1.3 to create a secure tunnel for data as it moves between systems, for instance, from an EHR system to a cloud data warehouse.
-
Encryption at Rest: Applying strong encryption standards like AES-256 to protect data while it’s sitting in databases, data lakes, or on backup tapes.
Data De-Identification Techniques
A lot of the time, we need data for analytics or research, but we don’t need to know the specific patient’s identity. Engineers use several clever techniques to strip out or obscure PHI:
-
Masking: Hiding parts of sensitive data with placeholder characters, like showing only the last four digits of a Social Security Number.
-
Tokenization: Swapping out a sensitive piece of data (like a patient ID) with a random, non-sensitive “token.” This token has no real-world value and can’t be reverse-engineered.
Given how personal healthcare information is, sticking to stringent data privacy rules is non-negotiable. It’s a global concern, where standards like ISO 27001 and data privacy laws provide a framework for information security. As we explored in our guide to HIPAA-compliant software development, building systems that are compliant from the very beginning is the only way forward.
Ultimately, managing patient consent and building privacy into every feature aren’t just legal obligations. They are engineering imperatives that build trust and ensure the ethical, responsible use of healthcare data.
Breaking Down Data Silos with Interoperability Standards
For decades, a massive problem has haunted healthcare: data silos. Think about it. A patient’s health story is often scattered across dozens of different, disconnected systems. Their primary care doctor has one piece, a specialist has another, the hospital has a third, and the pharmacy has yet another.
Each of these systems speaks its own digital language, making it a nightmare to get a single, complete view of the patient. This isn’t just an IT headache; it’s a genuine barrier to providing good, coordinated care and running any kind of advanced analysis.
The answer to this digital Tower of Babel is interoperability: getting all these different systems to talk to each other and share data smoothly. For a data engineer, this means building digital bridges between isolated islands of information. And to do that, you absolutely need to rely on modern data standards.
FHIR: The Universal Translator for Health Data
For a long time, the industry leaned on standards like HL7v2. They worked, but they were clunky, rigid, and a real pain for modern developers to use. Today, the clear winner and successor is FHIR (Fast Healthcare Interoperability Resources).
The best way to think about FHIR is as a universal power adapter for health data. You know how a good travel adapter lets you plug your laptop into any outlet, no matter where you are in the world? FHIR does the same thing for health information, offering a common, web-based way for any application to connect and share data. It’s built on modern web standards and APIs, which makes it infinitely more flexible and easier to work with than the old guard. As we’ve explored in our guide on FHIR integration, it’s the foundation of almost all modern health tech.
A well-built data pipeline uses FHIR to do three critical things:
-
Ingest Data: Pull information from EMRs, lab systems, and patient portals in a consistent format.
-
Normalize Data: Translate old or proprietary data formats into the clean, standardized FHIR structure.
-
Expose Data: Serve up this newly unified data through secure APIs so other applications can actually use it.
The result is a single, cohesive view of a patient’s entire journey. That’s the starting point for everything from managing the health of entire populations to delivering truly personalized medicine.
Creating a Unified Patient View
Ultimately, the goal of tearing down these silos is to build a single, comprehensive, longitudinal patient record. This becomes the source of truth, combining clinical data with financial and operational information in one place. This is where real technical skill comes into play. Getting a modern standard like FHIR to talk to a 20-year-old legacy system is a serious engineering challenge, one that often requires deep expertise in custom software development.
A unified data stream is the prerequisite for coordinated care. When a patient’s entire medical history is available to every provider at the point of care, it dramatically reduces medical errors, eliminates redundant testing, and leads to better health outcomes.
To really nail this, organizations have to align all kinds of data sources. This often means looking beyond just clinical data and implementing strategies like a robust CRM integration to connect patient communications and administrative records with their clinical history. By building these connections, data engineers ensure every piece of the puzzle helps create a clearer, more powerful picture of patient health.
Building Data Pipelines Ready for AI and Machine Learning
The real magic of healthcare data engineering happens when it starts feeding advanced artificial intelligence and machine learning models. It’s not enough to just collect data. The whole point is to build pipelines that turn that raw information into something that can predict the future, whether that’s forecasting patient readmissions, spotting diseases earlier, or making a hospital run more smoothly.
Building a pipeline for basic analytics is one thing, but getting data ready for machine learning is a whole different ballgame. AI models are incredibly finicky about the data they’re trained on. Quality, structure, consistency; it all has to be just right. A solid data pipeline is the absolute first step to making sure those models are accurate, dependable, and safe enough for clinical use.
This preparation stage is where organizations can truly start to see the potential of AI for your business, turning historical records into a powerful tool for predicting what comes next.
Crafting ML-Ready Datasets
An “ML-ready” dataset isn’t just a clean spreadsheet; it has specific traits that data engineering pipelines need to produce.
-
Feature Engineering: This is the art of creating the right input signals for a model. A data engineer might take a simple timestamp and turn it into more useful features like “day of the week” or “days since last hospital visit.” These are the details that help a model learn patterns.
-
Data Versioning: Code gets versioned, and so should data. If a model’s performance suddenly tanks, you have to be able to trace it back to the exact dataset version it was trained on to figure out what went wrong. It’s a non-negotiable for troubleshooting.
-
Reproducibility: In healthcare, you have to be able to prove how you got your results. Every step in the data preparation process, from cleaning to transformation, must be documented and repeatable. This is essential for clinical validation, regulatory approval, and building trust.
The pipeline is not just a delivery mechanism; it is an integral part of the machine learning model itself. The transformations and cleaning steps it performs directly influence the model’s accuracy and fairness.
The industry is clearly betting big on this. The global healthcare analytics market is expected to hit USD 263.36 billion by 2032, a huge jump from USD 69.12 billion in 2026. That’s a compound annual growth rate of 24.84%. This kind of growth shows just how serious the industry is about using data to make smarter decisions. You can dive deeper into the full market forecast from Research and Markets.
The Role of MLOps and Cloud Platforms
Trying to manage all this complexity manually is a recipe for disaster. That’s why organizations are turning to MLOps (Machine Learning Operations). Think of MLOps as a set of practices that automates the entire machine learning workflow, from prepping the data to deploying and monitoring the model. A strong data engineering pipeline is the foundation of any good MLOps strategy.
Cloud platforms like AWS, Azure, and Google Cloud are the workhorses that make this possible. They provide all the necessary tools, from massive storage options to managed services that make training and deploying models much simpler. As we covered in our guide on healthcare analytics implementation, using these cloud tools is fundamental to building powerful and flexible analytics systems.
Putting together these kinds of sophisticated, scalable pipelines is a central part of our AI development services. By blending solid data engineering with MLOps principles, we help healthcare organizations build automated systems that constantly feed high-quality, ML-ready data to their models, paving the way for a smarter future in healthcare.
Your Roadmap for a Winning Data Engineering Strategy
Building a healthcare data engineering practice from the ground up can feel overwhelming. It’s easy to get lost in the sheer scale of it all. The key is to stop thinking of it as one massive, monolithic project. Instead, picture it as a journey with distinct, manageable phases. Each step should build on the last, delivering real value along the way and generating momentum for what’s next. This phased approach lets you prove the concept quickly and scale up without getting ahead of yourself.
The timing couldn’t be better. We’re seeing huge growth in this space, largely fueled by new tech and the real-world application of AI. The big data healthcare market is on track to hit USD 378.07 billion by 2035 – a massive leap from USD 85.91 billion today. That’s a compound annual growth rate of 14.42%. For any organization that gets its data strategy right, the opportunity is immense. You can read more about these market projections to get a feel for the competitive environment.
Phase 1: Discovery and Assessment
This is your foundation. Before you write a single line of code, you need to ask the tough questions. The entire point here is to make sure your technical plan is directly tied to a tangible clinical or business outcome.
-
Map Your Data Sources: First, figure out where all your data lives. Create an inventory of everything from EMRs and billing platforms to lab information systems (LIS) and connected medical devices. You need to know their formats, how to access them, and frankly, how clean (or messy) they are.
-
Pick Your First Target: What’s the first problem you’re going to solve? Don’t try to boil the ocean. Pick something specific and high-impact, like reducing patient readmission rates, streamlining operating room schedules, or speeding up claims processing.
-
Get Everyone on the Same Page: This is critical. Pull together leaders from clinical teams, administration, and IT. Everyone needs to agree on the project’s scope and, most importantly, what a “win” actually looks like.
Phase 2: Foundational Setup and a Pilot Project
Once you have a clear goal, it’s time to start building. This phase is all about getting the core infrastructure in place and running a pilot project to prove this whole thing actually works.
A word of advice: choose a pilot project that’s both highly visible and achievable. Scoring a quick win is the single best way to get buy-in from the rest of the organization for the bigger, more ambitious projects down the road.
-
Choose Your Tools: Decide on your cloud platform, whether it’s AWS, Azure, or Google Cloud, and select the right tools for pulling data in, storing it, and shaping it for use.
-
Build That First Pipeline: Now, you’ll develop the data pipeline for your pilot. This is where you connect to the sources you found in Phase 1, clean and transform the data, and load it into a secure, accessible spot. For instance, you could build a pipeline that merges patient admission and discharge data to start predicting who is at high risk for readmission.
Phase 3: Scale and Govern
With a successful pilot under your belt, it’s time to expand. This phase is all about bringing in more data sources and tackling more use cases. But as you grow, you have to put strong guardrails in place to make sure your data stays reliable, secure, and easy to find.
-
Broaden Your Scope: Start onboarding the next set of data sources and building pipelines for other high-priority problems you identified back in the discovery phase.
-
Establish Governance: It’s time to implement a real data governance framework. This means defining who owns what data, creating a data catalog so people can find what they need, and setting up automated monitoring to catch quality issues.
-
Build the Dream Team: You can’t do this alone. A great data team is a mix of different skills: Data Engineers to build the pipes, Data Analysts to find insights, Clinical Informatics Specialists to provide context, and a Product Owner to steer the ship.
Lessons from successful client cases consistently show that a flexible, hands-on approach is what works. As an experienced AI solutions partner, we specialize in guiding organizations through each of these phases, making sure the roadmap doesn’t just sit on a shelf but leads to a powerful and lasting data foundation.
Frequently Asked Questions About Healthcare Data Engineering
What’s the single biggest hurdle in this field?
The biggest challenge is the extreme complexity and fragmentation of healthcare data. Engineers must consolidate diverse data types, from structured EMR data and medical images to unstructured physician notes and real-time streams from IoT devices. Integrating these into a unified, reliable source of truth while strictly adhering to HIPAA and other privacy regulations is a significant and high-stakes undertaking.
What are the go-to tools and languages for a healthcare data engineer?
Python and SQL are the foundational languages for any data engineer in healthcare. A modern tech stack also typically includes:
-
Cloud Infrastructure: Scalable platforms like AWS, Azure, or Google Cloud Platform.
-
Big Data Processing: Frameworks like Apache Spark for transforming large datasets.
-
Workflow Orchestration: Tools such as Apache Airflow to manage and automate data pipelines.
-
Data Warehousing: Cloud-native solutions like Snowflake or Google BigQuery for optimized analytics.
How is healthcare data engineering different from other industries?
The primary differentiator is the immense ethical responsibility. While other industries focus on performance and profit, healthcare data engineering must prioritize patient privacy, security, and compliance with regulations like HIPAA above all else. This focus on protecting sensitive personal health information (PHI) shapes every architectural decision and adds a layer of accountability that is unique to the healthcare sector. The industry’s growth, with the healthcare business intelligence market projected to reach USD 16.53 billion by 2033 according to sources like OpenPR, is driven by this responsible approach to data.
Ready to build a secure, scalable data foundation for your healthcare organization? As a dedicated AI solutions partner, Bridge Global has the expertise to engineer data platforms that power life-saving insights.
About Shreesha Chandrabose
Shreesha Chandrabose is a commerce graduate with a growing passion for content writing and digital media. With a curious mind and a creative approach, she enjoys transforming ideas into simple, relatable, and engaging narratives. She loves poetry, photography, and editing, and enjoys bringing ideas to life through words and visuals.
View all posts by Shreesha Chandrabose →