


Healthcare Software Maintenance: A Complete Guide
A clinic doesn’t have to suffer a catastrophic outage to feel the cost of weak maintenance. A slow EHR during morning rounds, a failed interface between lab and billing, an access control mistake after a patch, or an AI recommendation engine drifting off course can all disrupt care long before anyone declares a formal incident.
That’s why healthcare software maintenance can’t sit in the same budget bucket as “post-launch support.” For a CTO, it’s an operating discipline that protects patient safety, preserves compliance, and determines whether the platform can absorb growth, integrations, and new clinical workflows without becoming fragile.
Teams that treat maintenance as a strategic capability make better decisions earlier. They build for patchability, auditability, rollback, observability, and controlled change. They also choose partners who understand that maintenance is part of the full lifecycle, not the cleanup phase. A strong healthtech software development partner sees software health as a continuing responsibility, not a warranty ticket.
Beyond Bug Fixes The Strategic Role of Healthcare Software Maintenance
In healthcare, maintenance failures show up in operational language first. Delayed appointments. Duplicate records. Missing audit trails. Clinical staff working around software instead of through it. By the time the issue reaches the CTO, the damage often includes trust erosion across clinical, compliance, and operations teams.
The mistake is thinking maintenance is mostly corrective work. Bug fixing matters, but it’s only one slice of the job. Real healthcare software maintenance keeps systems reliable under change. Regulations evolve, devices get replaced, security threats shift, integrations multiply, and user behavior exposes design weaknesses that never appeared in test environments.
What maintenance protects
A resilient maintenance program protects more than uptime. It protects:
-
Patient safety: Clinical systems must remain available, accurate, and predictable during care delivery.
-
Regulatory posture: Teams need traceable changes, defensible patching decisions, and clean access governance.
-
Operational continuity: Front-desk workflows, claims, lab interfaces, care coordination, and reporting all depend on stable software.
-
Innovation capacity: New AI features, remote monitoring, analytics, and patient-facing experiences only work when the core platform is maintainable.
Healthcare systems rarely fail because one bug appears. They fail because years of unmanaged changes make routine updates risky.
That’s the strategic shift many teams need. Maintenance isn’t what starts after delivery. It’s the mechanism that keeps a digital health product clinically usable, legally defensible, and technically adaptable.
The move from reactive to predictive
Reactive support asks, “What broke?” Mature maintenance asks, “What’s changing, what’s getting brittle, and where will the next failure come from?” That second mindset changes staffing, tooling, release planning, and architecture decisions.
It also changes how leaders evaluate software investments. A platform that ships quickly but degrades under routine updates becomes expensive fast. A platform built for maintainability gives the business room to scale safely.
The Four Pillars of Healthtech Software Maintenance
Most CTOs inherit a maintenance mix rather than a maintenance strategy. Tickets arrive, teams react, and over time every issue gets labeled “support.” That hides the work. In healthcare, maintenance falls into four pillars, and each one needs a different process, budget logic, and ownership model.
The market has moved in this direction for a reason. The global healthcare CMMS market was valued at USD 211.6 million in 2022 and is projected to grow at an 11.25% CAGR through 2030, with web and cloud-based solutions holding a 56.2% share in 2022, driven by preventive maintenance and regulatory compliance according to Grand View Research’s healthcare CMMS market analysis.
Corrective maintenance
This is emergency response. A broken medication alert, a failed patient portal login flow, an interface that stops transmitting radiology orders. Corrective work restores function after something goes wrong.
Corrective maintenance needs fast triage and clear severity definitions. Not every defect is a Sev 1, but healthcare teams often classify issues emotionally because users are under pressure. Good practice separates clinical risk from inconvenience, then routes work accordingly.
A few practical rules help:
-
Define impact clearly: Distinguish between care-blocking incidents, operational disruptions, and minor defects.
-
Attach rollback options: If a release causes instability, teams need a safe path back.
-
Capture root cause: Don’t close incidents with “fixed in production” and move on.
Adaptive maintenance
Adaptive maintenance keeps software functional as its environment changes. In healthtech, that often means new privacy requirements, payer rules, API changes, cloud policy updates, or integration with a new imaging or monitoring device.
This category is where many products accumulate hidden risk. Teams focus on visible feature work while environmental dependencies shift underneath them. An interface still works until the vendor changes authentication. A reporting engine is stable until retention rules change. Then what looked like a surprise was deferred adaptive work.
Perfective maintenance
Perfective work improves software that already functions. That might mean reducing clicks in a clinician workflow, cleaning up alert logic, improving search relevance, simplifying handoff screens, or refactoring a noisy dashboard.
This is the category that often gets cut first, and that’s a mistake. In healthcare, friction creates workarounds. Workarounds create safety and compliance exposure.
As we explored in our guide to healthtech product scaling and engineering support, software health depends on what happens after launch as much as what happens before it.
Preventive maintenance
Preventive maintenance is the discipline that keeps the system from becoming fragile. It includes dependency reviews, performance tuning, infrastructure updates, test suite hardening, audit log verification, backup validation, and proactive monitoring.
Think of it as the annual check-up that prevents emergency surgery later.
Practical rule: If your team can’t name the preventive work completed in the last quarter, you’re probably funding future incidents without realizing it.
A simple diagnostic
Use this quick lens with your team:
| Maintenance type | Typical trigger | Healthcare example | What goes wrong if ignored |
|---|---|---|---|
| Corrective | Something failed | Order entry defect blocks submission | Clinical disruption and urgent firefighting |
| Adaptive | External conditions changed | New compliance or device integration need | Sudden incompatibility |
| Perfective | Users struggle with the current flow | Clinician UI creates excessive manual steps | Workarounds and lower adoption |
| Preventive | Risk detected before failure | Dependency updates and monitoring improvements | Growing fragility |
Navigating the Compliance and Security Maze
Healthcare maintenance gets harder the moment a patch, workflow update, or interface change touches protected data or core clinical operations. The technical question is never just, “Can we deploy this fix?” The fundamental question is, “Can we deploy it without creating a privacy, safety, or continuity problem?”

The patching problem is a good example. Frequent or large software patches can create meaningful operational disruption, and a healthcare patching study notes four core mitigation actions: staged rollouts, staff training before deployment, contingency planning for disruptions, and proper system configuration. The same study also notes that 73% of healthcare organizations use legacy systems that often miss the latest security updates, which makes poor patching decisions even riskier according to this PMC review on patching-related disruption in healthcare.
Why patching fails in clinical settings
Most failed patch cycles aren’t caused by bad intent. They fail because healthcare environments are interconnected and unforgiving. A change that looks small in a ticket can ripple across identity systems, clinical interfaces, documentation flows, and downstream reporting.
Common failure patterns include:
-
Weak release sequencing: Teams patch the application before validating connected systems.
-
Limited frontline training: Nurses, administrators, or technicians see changed behavior with no advance guidance.
-
No failover playbook: When a deployment degrades performance, staff improvise.
-
Configuration drift: Interfaces and permissions vary across environments, so testing gives false confidence.
That’s why compliance work has to live inside maintenance operations, not beside them.
What disciplined maintenance looks like
A maintainable healthcare environment usually has a few visible characteristics:
-
Change approval with clinical context: Security and engineering don’t approve changes in isolation when workflows affect care delivery.
-
Role-based access reviews: Permissions are revisited after every major system change, not only during annual audits.
-
Environment parity: Test environments should reflect production behavior closely enough to expose interface and policy issues.
-
Evidence capture: Teams keep records of what changed, who approved it, what was tested, and how rollback would work.
For many organizations, formal cyber compliance solutions become necessary. Manual evidence gathering and informal patch approvals don’t scale.
Good maintenance creates an audit trail by default. Bad maintenance asks people to reconstruct one after an incident.
A practical reference point is our guide to SOC 2 compliance requirements, which maps well to the broader discipline of controlled change, traceability, and operational accountability.
Security has to be built into maintenance
Security can’t be a clean-up activity after engineering ships a change. It has to shape release design from the start. That means dependency policies, secrets management, access reviews, logging standards, retention controls, and rollback procedures all belong in the maintenance program.
The best CTOs make one cultural shift here. They stop asking teams to “move fast but be careful” and instead design a process where careful is what enables speed.
Choosing Your Maintenance Model In-House Outsourced or Hybrid
Maintenance model decisions usually start as staffing conversations. They shouldn’t. They’re governance decisions first. The right model depends on how critical the software is, how often it changes, how much legacy complexity you carry, and whether your internal team can support regulated delivery without burning out.
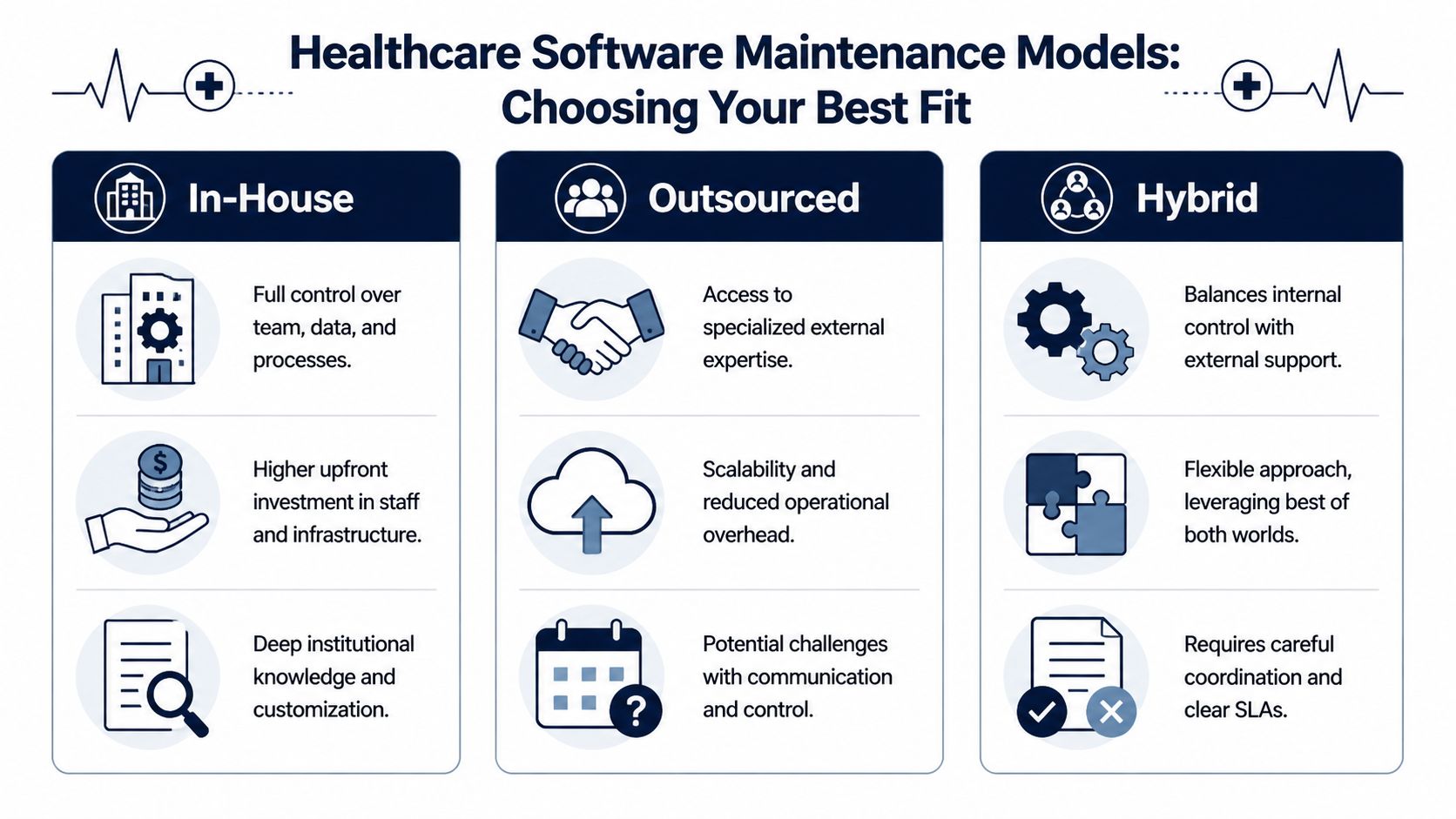
No model is universally best. Each one solves a different operating problem.
In-house works when control is the priority
An in-house team fits best when the product is tightly tied to clinical workflows, proprietary logic, or sensitive organizational knowledge. You get direct oversight, faster institutional learning, and tighter coordination with compliance, product, and operations.
The downside is capacity. Internal teams often become overloaded by feature delivery, production support, and security work at the same time. When that happens, preventive maintenance slips first.
Outsourced works when specialization and scale matter
An outsourced model can make sense when you need faster access to specialized skills, broader coverage windows, or a team already familiar with regulated engineering practices. This is especially useful for legacy stabilization, platform modernization, QA automation, or cloud operations that your core team doesn’t want to build from scratch.
The trade-off is distance. If governance is weak, the vendor becomes a ticket processor instead of a maintenance partner. Communication standards, ownership lines, and service levels matter more than logos.
Hybrid is often the practical answer
Many healthcare organizations land on hybrid for good reason. Internal teams keep ownership of architecture, risk, and business priorities. External teams handle agreed slices such as monitoring, testing, patch execution, integration support, or structured backlog reduction.
This model works only when responsibilities are explicit. Hybrid without clear boundaries creates duplicate work and finger-pointing during incidents.
Comparison of Healthcare Software Maintenance Models
| Criterion | In-House | Outsourced | Hybrid |
|---|---|---|---|
| Control | Highest direct control | Lower day-to-day control | Shared control |
| Specialized expertise | Limited to current hiring success | Broad if partner is strong | Broader than in-house alone |
| Scalability | Slower to expand | Faster to expand | Flexible |
| Institutional knowledge | Strongest | Requires transfer and documentation | Balanced |
| Response coordination | Direct internal alignment | Depends on SLA discipline | Strong if governance is mature |
| Best fit | Core clinical platforms | Specialized or overflow support | Most growing healthtech environments |
The decision criteria CTOs should use
Ask these questions before choosing:
-
How much legacy complexity do we own? Fragile systems need specific maintenance experience.
-
Where does clinical risk sit? High-risk workflows may need closer internal control.
-
What skills are consistently missing? Security, DevOps, QA automation, interoperability, and AI ops are common gaps.
-
Can we govern external delivery well? If not, outsourcing won’t fix the problem.
-
Do we need continuity beyond business hours? Support coverage changes the staffing model.
If your organization needs external support, choose for operating fit, not just cost. A dedicated development team can help, but only if the engagement model includes clear ownership, release discipline, and measurable service expectations.
Modernizing Your Maintenance Processes and Tooling
A weak maintenance program usually looks busy from the outside. Tickets move. Hotfixes ship. People stay online late. None of that proves the system is healthy. Modern healthcare software maintenance depends on process design and tooling that reduce chaos before incidents happen.
The first thing to fix is release mechanics. If code changes, infrastructure updates, security patches, and configuration edits move through different channels with inconsistent validation, the platform will stay brittle no matter how skilled the team is.
Build a predictable delivery engine
Generally, the core stack should include source control, automated testing, deployment pipelines, centralized logging, alerting, and structured issue tracking. CI/CD isn’t just a speed tool. In healthcare, it’s a control mechanism that makes changes reviewable, testable, and reversible.
A sound release path usually includes:
-
Standardized branching and approvals so urgent fixes don’t bypass all review.
-
Automated regression testing for clinical workflows, access rules, and integrations.
-
Environment-specific checks to catch configuration mismatches before deployment.
-
Controlled rollout patterns such as phased deployment where possible.
-
Post-release validation tied to real operational signals, not just “deployment succeeded.”
Tooling should expose risk, not hide it
Many organizations still depend on tribal knowledge for maintenance. One engineer knows the cron jobs. Another knows the interface server. Someone in compliance remembers which report proves a control. That’s not resilience. That’s luck.
Use tooling to make system health visible:
-
Observability platforms: Track errors, latency, queue failures, and unusual usage patterns.
-
Dependency scanners: Identify outdated components before they become emergency work.
-
Service desk workflows: Tie incidents, change requests, and problem records together.
-
Runbooks: Document response steps for recurring failure modes and common rollback paths.
The economics favor this discipline. The legacy burden is real. Retrofitting security into existing applications costs 3 to 5 times more than building it in from the start, and the average healthcare data breach costs $9.77M, as outlined in Sidebench’s overview of common health tech challenges.
If a maintenance process depends on memory, it will fail during the exact incident when clarity matters most.
Measure what actually improves reliability
Maintenance metrics should help you make decisions, not decorate a dashboard. Track a small set consistently:
-
Uptime by critical service
-
Mean time to detect
-
Mean time to resolution
-
Change failure rate
-
Patch backlog by severity
-
Aging unresolved incidents
-
Test coverage for high-risk workflows
These measures matter only if they trigger action. A large backlog with no aging policy is just delayed risk.
Maintenance modernization also works best when aligned with broader product engineering services and a disciplined custom software development practice. The operating model matters as much as the codebase.
The AI Revolution in Predictive Healthcare Maintenance
A medication reconciliation module slows down during peak clinic hours. Support sees a few complaints, engineering clears the queue, and everyone moves on. Two weeks later, the same pattern contributes to delayed chart updates, a failed interface job, and an avoidable compliance review. That is the cost of treating maintenance as a series of isolated tickets.

AI changes the job when teams use it to spot failure patterns early enough to act on them. In healthcare, that matters because small technical signals often sit upstream of patient safety, audit exposure, and revenue disruption. The goal is not smarter dashboards. The goal is earlier intervention.
The practical inputs are already familiar. Logs, ticket history, infrastructure telemetry, release data, user behavior, and support notes can all be used to identify precursors to failure that a human reviewer will miss under time pressure. Common examples include rising retry rates, unusual authentication activity, response-time drift in a clinician-facing workflow, or a recommendation model producing less reliable outputs after a data shift.
Where AI creates real maintenance value
The strongest use cases are operational and measurable:
-
Anomaly detection: Identify abnormal system behavior before users report it.
-
Ticket triage support: Cluster similar incidents, suggest likely root causes, and route work to the right team faster.
-
Dependency risk prediction: Flag libraries, services, or integrations linked to repeat instability.
-
Release risk scoring: Estimate which changes are more likely to trigger downstream failures.
-
Clinical model monitoring: Detect drift, degraded performance, or broken assumptions in production AI tools.
For CTOs, the strategic value is straightforward. Predictive maintenance helps teams decide what to fix first, when to schedule intervention, and where to add safeguards before a defect becomes a patient-facing event. That changes maintenance from reactive support into an operating discipline that protects care delivery and margins at the same time.
This is especially important for AI-enabled clinical products. Authors in this NIH article on AI-driven clinical decision support systems describe long-term verification and validation as a major barrier to deployment because these systems must keep adapting to new data and regulatory requirements without introducing harmful errors. In practice, that means maintenance teams need to monitor model behavior continuously, not just the surrounding application stack.
A useful reference point is our guide to AI solutions for healthcare, particularly for leaders defining how AI operations, software reliability, and clinical governance should work together.
What separates useful prediction from expensive noise
I have seen teams buy AI tooling before they can answer a basic question like which workflow fails most often after a release. That sequence usually wastes budget.
Predictive maintenance works when a few conditions are in place:
-
Baseline observability exists: The model needs reliable telemetry, event history, and enough context to distinguish noise from risk.
-
Human review stays in the loop: In regulated environments, predicted risk should inform decisions, not replace them.
-
Feedback data is captured: Resolved incidents, false positives, rollback outcomes, and postmortems should feed model tuning.
-
Governance applies to the AI layer too: Monitoring, validation, access controls, and documented change approval should cover the prediction system itself.
The trade-off is real. More aggressive alerting can catch issues earlier, but it can also flood teams with low-value signals. More conservative models reduce noise, but they miss weak signals that matter in high-risk workflows. The right threshold depends on the clinical and operational cost of being wrong.
Organizations exploring AI development services or an ai transformation framework should treat predictive maintenance as part of the core operating model. In healthcare, it is not a side experiment. It is a practical way to reduce avoidable incidents, strengthen compliance readiness, and create room for growth without scaling support chaos.
Your Implementation Roadmap Cost ROI and Getting Started
Healthcare software maintenance improves when leaders stop treating it as one giant transformation project. The better approach is staged. Audit the current state, stabilize the riskiest failure points, modernize the operating model, then add predictive capabilities where the underlying data is strong enough.
The financial case is stronger than many teams assume. Emergency repairs cost 4.8 times more than planned maintenance, major hospitals can lose an average of $1.5 million annually from unplanned equipment failures, and predictive algorithms can cut downtime by up to 35% while extending asset life by 15 to 20%, according to Oxmaint’s healthcare maintenance guide. Even if your stack is software-first rather than equipment-heavy, the logic still applies. Planned intervention is cheaper than emergency recovery.
A lean roadmap for startups
Startups usually don’t need a giant ITIL program. They need discipline where failure would damage trust fast.
Focus on this order:
-
Map critical workflows such as patient onboarding, billing, clinical documentation, and notifications.
-
Define severity and ownership so incidents have a clear path.
-
Set a patch and release cadence instead of patching ad hoc.
-
Instrument the platform with logging, alerting, and basic service health dashboards.
-
Document the minimum runbooks for rollback, access issues, and integration failures.
For early products, the goal is stability without bureaucracy. If you’re building from scratch, maintenance should influence architecture choices from day one. That’s one reason custom healthcare software development should include supportability, auditability, and observability in the initial scope.
A structured roadmap for enterprises
Enterprises usually have a different problem. They already have maintenance activity, but it’s fragmented across teams, vendors, legacy systems, and governance silos.
Use a phased program:
-
Baseline the estate: List applications, integrations, owners, dependencies, support status, and business criticality.
-
Classify risk: Separate care-critical systems, compliance-critical systems, and administrative platforms.
-
Standardize change control: Align patching, testing, release evidence, and rollback expectations.
-
Reduce legacy hotspots: Prioritize systems where each change is unusually expensive or risky.
-
Add predictive layers selectively: Start where monitoring data is strongest and impact is easiest to measure.
How to think about ROI
Don’t calculate ROI from labor savings alone. In healthcare, the return often comes from avoided disruption.
Look at:
-
Reduced unplanned downtime
-
Lower incident escalation effort
-
Fewer failed releases
-
Less audit remediation work
-
Improved clinician productivity
-
Lower exposure from aging unsupported components
A good maintenance plan also protects future delivery. New integrations, AI features, and reporting initiatives move faster when the environment is stable.
Operator insight: If every major feature requires a production war room, the real cost problem isn’t delivery. It’s maintainability.
If you need examples of what disciplined software delivery and ongoing support can look like in practice, reviewing relevant client cases can help teams calibrate expectations.
Frequently Asked Questions
A maintenance program usually reveals its quality during a bad week. A vulnerability drops on Monday, an integration starts timing out on Tuesday, and by Wednesday the team is arguing about whether a recurring issue is a bug, a data problem, or an infrastructure fault. Good answers matter here because they shape policy, staffing, and investment decisions before the next incident hits.
How often should healthcare software be patched
Set patch cadence by risk, system role, and validation effort. Internet-facing components and known high-severity vulnerabilities need rapid action. Clinical systems, revenue cycle platforms, and integration engines often require scheduled testing and tighter release coordination because a rushed patch can break a workflow that matters to care delivery.
The right question is not “monthly or quarterly.” It is whether each system has a defined patch window, an exception path, and a tested rollback plan.
What’s the biggest maintenance mistake CTOs make
Treating maintenance as spare capacity is still the most common failure pattern I see. Feature work wins attention. Maintenance debt keeps growing in the background until release risk, support cost, and audit effort all rise at once.
Teams that run well do three things differently:
-
assign named owners for each critical application and integration
-
fund preventive work as an operating requirement, not a leftover task
-
track repeat incidents and aging components as management signals, not technical trivia
Can legacy healthcare platforms still be maintained safely
Yes, for a defined period, if the organization is honest about the constraints.
Legacy systems usually bring higher regression testing effort, custom interface handling, fewer available engineers, and more security exceptions to document. They can remain in service if access is tightly controlled, dependencies are mapped, monitoring is active, and replacement planning has a date and budget behind it. Unsupported software that “has been stable for years” is often one change away from a service disruption or audit problem.
Should AI be used in maintenance for regulated healthcare systems
Yes, with controls. AI is most useful in maintenance when it helps teams spot anomaly patterns earlier, prioritize incident queues, flag risky releases, and identify failure signals across logs, tickets, and dependencies that humans miss under time pressure.
That makes it a strategic tool, not a novelty feature.
For regulated environments, keep the boundaries clear. Use AI to support prediction and triage. Keep human review for changes that affect patient safety, protected data, compliance decisions, or production releases. If the model influences operational decisions, teams also need validation records, auditability, and a way to explain why a recommendation was made.
What should be in a maintenance SLA
A healthcare SLA needs more than response times. It should define severity levels, ownership, escalation rules, communication timing, release windows, rollback expectations, backup checks, and evidence requirements for regulated changes.
It should also remove ambiguity. State what counts as an incident, what counts as routine service work, and what becomes a billable enhancement or project request.
How do you know your maintenance program is improving
Measure what improves reliability.
Start with a small set of signals that leaders and operators both trust: repeat incident rate, change failure rate, time to restore service, overdue patch exceptions, and the number of critical workflows relying on manual workarounds. Then add one business-facing measure, such as clinician disruption, claims processing delays, or support volume tied to a specific platform.
If predictive maintenance is working, teams should see issues earlier, not just resolve them faster.
When should a company move from reactive support to predictive maintenance
Move once your operational data is good enough to support useful predictions. That means logs are retained, incidents are categorized consistently, dependencies are visible, and release history can be tied to production outcomes.
If those basics are weak, AI will produce noise. If they are stable, predictive maintenance can reduce downtime, improve compliance readiness, and create room for growth because teams spend less time firefighting and more time preventing failures. That is the point where maintenance stops being a cost center and starts protecting revenue, patient trust, and delivery speed.
Healthcare software rarely fails all at once. It degrades through unmanaged change, rushed fixes, and delayed modernization. If you want a more resilient maintenance program, stronger compliance posture, and a practical path toward AI-enabled reliability, Bridge Global can help you assess the current state, modernize your delivery model, and build software that stays safe, stable, and future-ready.
About Preethi Saro Philip
Preethi Saro Philip is a Post Graduate Research Degree holder in Economics with more than 10 years of experience in writing, editing, research and teaching. She has an intense passion for content crafting and calls herself a ‘wordsmith’. She enjoys writing on wide-ranging topics including business, technology, health & lifestyle, education, environment etc.
View all posts by Preethi Saro Philip →