


A Guide to Healthcare Data Platform Engineering
Healthcare data platform engineering is all about building a single, reliable digital backbone for a modern health system. It’s the behind-the-scenes work that tackles the massive problem of siloed, messy data and creates a single source of truth. In short, this specialized field is completely changing how healthcare organizations manage and use their most valuable asset: information.
Building the Central Nervous System of Modern Healthcare
Think about all the data a typical hospital juggles. You have patient details in the Electronic Health Records (EHR), lab results in another system, pharmacy data in a third, and a constant flood of new information from medical imaging and wearable devices.
Without a unified platform, this data is like a library with books written in a hundred different languages, scattered across different buildings. It’s disorganized, inaccessible, and practically impossible to use for anything advanced.
This is exactly the problem healthcare data platform engineering sets out to solve. It’s the practice of building that “library,” translating all the “books” into a common language, and organizing them so doctors, researchers, and even AI can find what they need, when they need it. It’s about creating a digital backbone that makes information clean, accessible, and ready for analysis, which is what allows patient care to shift from being reactive to proactive.

Why is This Work Gaining So Much Attention?
The move toward data-driven healthcare isn’t just a trend; it’s a financial and operational necessity. The money tells the story: the healthcare data technology market was valued at USD 3.10 billion in 2024 and is expected to hit USD 9.5 billion by 2033, growing at a 13.36% CAGR.
What’s really telling is that in 2024, a massive 66.55% of the market’s revenue came from data integration. This shows just how urgent the need is to bring together all those disparate datasets from EHRs, clinical trials, and claims and turn them into something cohesive and ready for analysis.
At its heart, a modern healthcare data platform must perform a few critical jobs to unlock the true value of an organization’s data.
Core Functions of a Healthcare Data Platform
This table outlines the essential responsibilities of a data platform and the direct business value each one provides.
| Core Function | Description | Business Value |
|---|---|---|
| Data Ingestion | Creates reliable, automated pathways to pull data from all sources (EHRs, labs, wearables, etc.). | Ensures no data is left behind, providing a complete picture of patient and operational activities. |
| Data Standardization | Translates all incoming data into a common format and terminology, like FHIR or OMOP. | Eliminates data silos and allows different systems to "speak the same language," enabling true interoperability. |
| Data Governance | Enforces rules for security, privacy, and compliance (e.g., HIPAA) across the entire dataset. | Mitigates risk, builds patient trust, and ensures data is used ethically and legally. |
| Data Accessibility | Provides secure, user-friendly tools and APIs for clinicians, researchers, and analysts to access data. | Empowers users to answer their own questions, speeding up research, improving clinical decisions, and fostering innovation. |
By focusing on these core functions, platform engineering builds the foundation that supports everything from day-to-day clinical decisions to groundbreaking medical research.
"The core mission is to build, maintain, and improve the components… specifically focused on defining and streamlining efficient data architectures, the management and maintenance of data sources across premises and platforms, and the enablement of AI/ML models and workflows."
The Broader Context in Health Tech
Healthcare data platform engineering doesn't exist in a vacuum; it’s a critical piece of the larger health technology puzzle. The quality and accessibility of data directly determine whether a new application or software tool will succeed or fail.
To really grasp why this specialized work is so crucial, it helps to understand the wider world of software engineering in healthcare. That foundational knowledge puts the specific challenges of data engineering into perspective, making it crystal clear why a dedicated, expert approach is no longer optional.
Designing Your Health Data Platform Architecture
Think of building a health data platform like laying the groundwork for a major medical research campus. You can't just throw up a few buildings; you need a master plan. You need carefully planned roads for supplies to get in (Data Ingestion), secure warehouses to store them (Data Storage), and a sophisticated lab to turn those raw materials into breakthroughs (Data Processing). Getting this architectural blueprint right from day one is the most critical step in healthcare data platform engineering.
First, let's talk about getting data into the system. The Data Ingestion layer acts as the main gateway, pulling information from a dizzying array of sources that rarely speak the same language.
-
Electronic Health Records (EHRs): This is your bread and butter, typically accessed through APIs or direct database connections to get patient histories, notes, and orders.
-
Lab Information Systems (LIMS): Here, you’re pulling in highly structured, critical data like blood test results and pathology reports.
-
IoT and Wearable Devices: Think constant streams of data from continuous glucose monitors, smartwatches, and other patient-worn sensors. It’s high-volume and needs to be handled in real-time.
-
Medical Imaging (DICOM): This involves integrating massive, complex files from PACS (Picture Archiving and Communication System) servers, like MRIs and CT scans.
A well-designed ingestion strategy ensures you’re not just collecting data, but creating a continuous, reliable flow of information. It's the foundation for building a truly comprehensive view of patient health.
Choosing Your Storage Model: Data Lakes vs. Warehouses
Once data is flowing in, you need to decide where to put it. For years, the choice has been between two core models: the data warehouse and the data lake. A data warehouse is like a meticulously organized pharmacy, where everything is cleaned, labeled, and stored in a specific place. It’s perfect for structured data that’s already been processed for a known purpose, like financial reporting or operational dashboards.
A data lake, on the other hand, is more like a massive research library's entire collection: including old manuscripts, new journals, and even scribbled notes. It holds vast quantities of raw data in its native format, whether it's structured, semi-structured, or completely unstructured. This approach gives data scientists the freedom to explore and ask questions you haven't even thought of yet, making it perfect for machine learning.
But what if you need both? A third model, the Data Lakehouse, has become the go-to for modern healthcare platforms. It merges the scalability and flexibility of a data lake with the reliability and performance of a warehouse. It’s a hybrid that gives you one unified system for everything from BI reports to cutting-edge AI development.
No matter the model, the goal is to bring disparate data streams into one central hub.
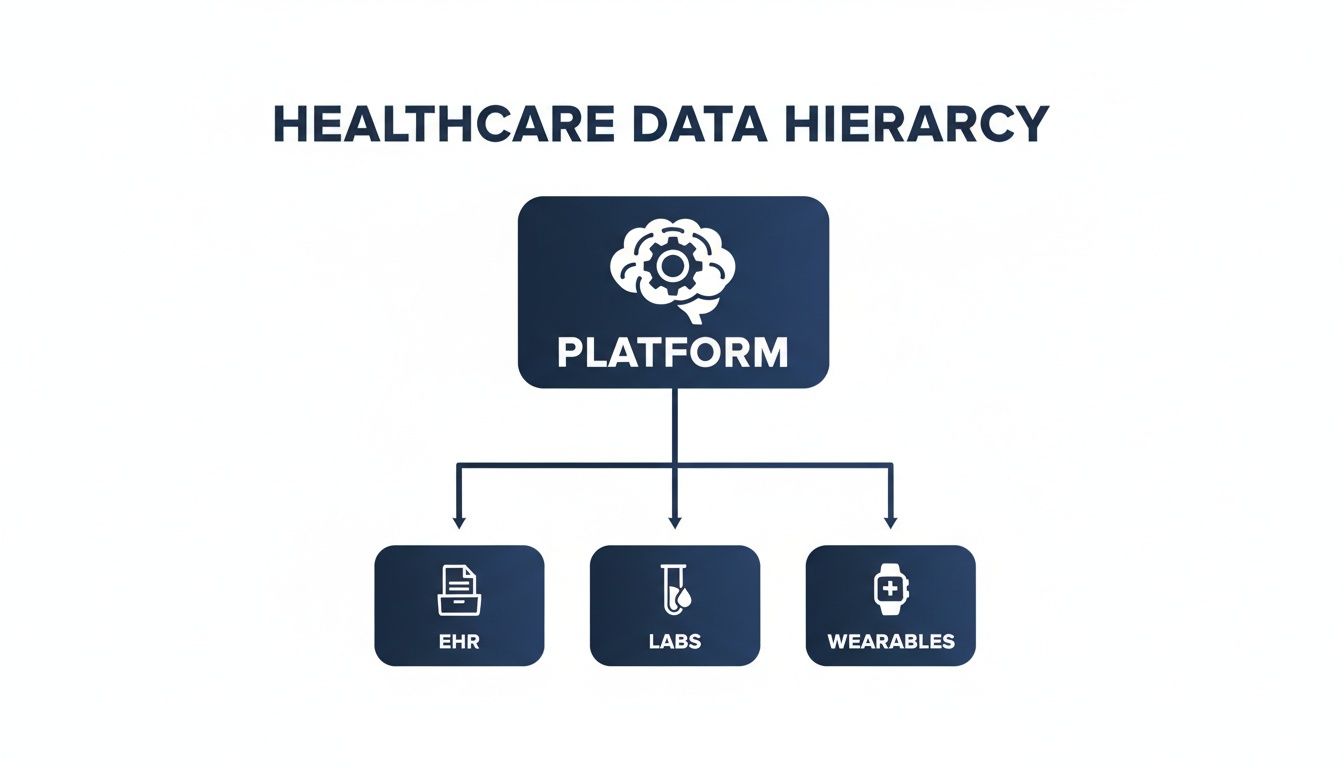
This unified view is what turns siloed information from EHRs, labs, and wearables into a powerful, cohesive intelligence engine.
Powering the Platform with Data Processing
The final piece of the architectural puzzle is Data Processing. This is the engine room where raw, messy data is transformed into a clean, standardized, and usable asset. This is where ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) pipelines do their magic, cleaning data, mapping it to standards like FHIR, and getting it ready for analysts and algorithms.
This work generally happens in one of two ways:
-
Batch Processing: Think of this as end-of-day accounting. Data is gathered over a period, like a day or an hour, and then processed all at once in a large batch. It's incredibly efficient for things that don't need to be instant, like running daily reports or updating billing cycles.
-
Stream Processing: This is the real-time heartbeat of the platform. Data is processed the moment it arrives, second by second. This is absolutely essential for use cases like monitoring a patient's vitals in the ICU for early warning signs or flagging a potentially fraudulent claim the instant it’s submitted.
Ultimately, there is no single "best" architecture. The right design hinges entirely on your organization's specific needs. Are you building a system to power real-time clinical alerts, or are you creating a foundation for long-term population health research? As we’ve covered before in our discussion on software engineering in healthcare, a solid technical foundation is what makes it possible to deliver real-world value.
Ensuring Security, Compliance, and Data Interoperability
When we talk about healthcare data platform engineering, security and interoperability aren't just add-on features. They're the absolute foundation. We're dealing with Protected Health Information (PHI), which means safeguarding data and making sure systems can actually talk to each other are non-negotiable.
These two pillars, compliance and interoperability, shape the entire design of a successful health data platform. Without them, the platform isn’t just useless; it’s a massive liability for patients and your organization. Think of it this way: security is the vault protecting priceless information, while interoperability is the universal key that allows the right doctors to access what’s inside, no matter where they are.

Demystifying Healthcare Compliance
At first glance, regulations like the Health Insurance Portability and Accountability Act (HIPAA) in the U.S. or the General Data Protection Regulation (GDPR) in Europe can feel like a tangled web of rules. But it’s much more helpful to see them as what they are: blueprints for building trust. They give us a clear framework for responsible data governance.
A truly compliant platform isn't just about checking boxes; it's about embedding security into its very DNA. Here are the core measures we always build in:
-
Encryption at Rest and in Transit: This is fundamental. It ensures data is scrambled and unreadable, whether it's sitting in a database or flying across a network.
-
Data Masking and Anonymization: When data is used for analytics or research, we strip or obscure personal identifiers. This lets us find valuable insights without ever compromising patient privacy.
-
Role-Based Access Control (RBAC): This principle is simple but powerful: people should only see the data they absolutely need to do their job. A surgeon has different access needs than a billing administrator, and the system must enforce that.
-
Comprehensive Audit Trails: Every single time data is touched: accessed, changed, or even just queried, it gets logged. This creates an immutable record, which is crucial for accountability and spotting security issues.
Trying to bolt on compliance after the fact is a recipe for disaster. That’s why any serious custom healthcare software development project must treat governance as a Day One priority, often by working alongside experts in cyber compliance solutions.
The Universal Translators of Healthcare Data
Interoperability is just a fancy word for getting different systems and devices to speak the same language. It's their ability to access, share, and use data together in a coordinated way. Without it, patient information gets stuck in digital silos, which leads to fragmented care, repeated tests, and even dangerous medical errors.
A lack of interoperability has a real human cost. When a patient arrives at an emergency room, their primary care physician’s records and recent lab results from another facility should be instantly available. Interoperability makes this possible, turning fragmented data points into a coherent patient story.
This is exactly where standards like HL7 and FHIR come into play. They act as the "universal translators" for health data.
-
HL7 (Health Level Seven): While it's an older standard, HL7v2 is still the workhorse inside most hospitals. It reliably handles critical messages, like sending a new lab order from the EHR to the lab's information system.
-
FHIR (Fast Healthcare Interoperability Resources): This is the modern, API-first standard built for the web. FHIR is what allows a patient's smartphone app to communicate seamlessly with a hospital's EHR. As we've discussed before regarding FHIR integration benefits, its flexibility is what’s powering the next generation of health apps.
A well-architected platform has to be bilingual. It must support legacy standards like HL7 to connect with older hospital systems while also fluently speaking FHIR to integrate with modern digital tools. To get a deeper understanding of the specific technologies that make this possible, exploring guides on healthcare interoperability solutions is a great next step.
Building and Managing Resilient Data Pipelines
Think of data pipelines as the circulatory system of your healthcare platform. They are the automated pathways that move information from all its different sources into a central place where it becomes truly useful. Getting this right, building pipelines that are resilient, scalable, and easy to manage, is a fundamental skill for any data engineering team in healthcare.
The whole process generally follows a pattern called ETL (Extract, Transform, Load) or its increasingly popular cousin, ELT (Extract, Load, Transform). This is the basic recipe for taking raw, often messy, data and turning it into something clean and reliable enough for analysis, reporting, or even training an AI.
The ETL Lifecycle in Healthcare
Building a pipeline that won't break under pressure means getting each step of this journey right. From grabbing raw data feeds out of an EHR to serving up clean data for a machine learning model, every phase needs smart planning and solid automation.
-
Extract: This is where it all starts – pulling data from its source. In healthcare, those sources are all over the map. You might be connecting to structured SQL databases for billing, tapping into real-time JSON feeds from wearable device APIs, or parsing complex DICOM files from medical imaging archives. A good extraction process has to be ready for anything, gracefully handling API timeouts, network hiccups, or sudden changes in how the source data is formatted without losing a single byte.
-
Transform: Once you have the raw data, you'll find it’s rarely ready to use. This is where the real cleanup work begins. Transformation involves fixing incorrect entries, standardizing formats (like converting every date to the universal ISO 8601 standard), and translating proprietary codes into industry standards like LOINC or SNOMED CT. Honestly, this is often the most challenging part, because it’s where you make sure all your data starts speaking the same language.
-
Load: Finally, the clean, transformed data is loaded into its new home. This is usually a data warehouse for structured analytics or a data lakehouse, which offers more flexibility for large-scale analysis and AI model training. The key here is making sure the loading process is both fast and completely verifiable, so you can trust the integrity of the data you’re storing.
Batch vs. Stream Processing: A Critical Choice
Not all data moves at the same speed, and it doesn't have to. Deciding whether to use batch or stream processing is a major architectural choice that depends entirely on what you're trying to accomplish.
-
Batch Processing: This is the workhorse for any data that isn't extremely time-sensitive. Here, data is gathered and processed in large, scheduled chunks: maybe once an hour, overnight, or even weekly. It's perfect and cost-effective for tasks like generating end-of-month financial reports or updating population health dashboards.
-
Stream Processing: This is for the "right now" data. Information gets processed in real time, the moment it’s created. Think about an ICU system monitoring a patient’s vitals to catch the earliest signs of sepsis, or an app that flags a potentially fraudulent claim the second it’s submitted. Streaming is absolutely essential for real-time alerts and immediate operational decisions.
A mature healthcare data platform doesn't pick one over the other; it uses both. It runs stream processing for critical, time-sensitive clinical events while using cost-effective batch processing for analytics and reporting that can wait a bit.
Getting these complex data flows built and running smoothly requires specialized expertise. A dedicated development team can seriously speed up the process, putting the right automation and monitoring in place to ensure your pipelines are reliable and performant. This guarantees that the data, the lifeblood of your platform, is always flowing where it needs to go.
Unlocking Value with AI and Advanced Analytics
Let's be honest: the whole point of building a sophisticated healthcare data platform isn't just to store data; it's to launch game-changing AI and analytics initiatives. This is where all the hard work in architecture and pipeline engineering truly begins to pay dividends, turning clean, unified data into life-saving insights and smarter operations. Once that solid foundation is in place, you can finally stop wrestling with basic reports and start asking the predictive questions that actually move the needle.
This is the leap from simply collecting data to taking intelligent action. Your platform becomes the refinery, taking in raw information and producing the high-octane fuel: clean, standardized, and ready to go, that every AI model needs to run accurately. Without it, even the most advanced algorithms are dead in the water.
From Raw Data to Predictive Power
With a truly unified data source, you can start building applications that were once pure science fiction. Your platform becomes the central nervous system for running complex models that can fundamentally change how care is delivered.
Imagine what becomes possible:
-
Predicting Disease Outbreaks: Public health teams can analyze population-level data to see where a disease might spike next, allowing them to get ahead of it with targeted resources and interventions.
-
Crafting Personalized Treatment Plans: Machine learning can sift through a patient's unique genetic profile, lifestyle factors, and clinical history to pinpoint the therapy most likely to work for them.
-
Unlocking Insights from Clinical Notes: Using Natural Language Processing (NLP), you can instantly scan millions of unstructured notes to find what doctors might miss: unreported side effects, subtle symptoms, or adverse drug reactions buried in text.
These aren't just hypotheticals. They show a real shift from reactive, symptom-based care to a proactive and predictive model of medicine.
MLOps: The Engine for Sustainable AI
Getting a predictive model to work once is a great start, but it's just that – a start. To deliver real, continuous value in a clinical setting, you need a disciplined process for managing the entire AI lifecycle. This is exactly what MLOps (Machine Learning Operations) provides, and your data platform is its operational heart.
MLOps bridges the often-siloed worlds of data science and IT operations. It creates an automated, repeatable system for training, deploying, and monitoring machine learning models. This ensures your AI initiatives aren't just one-off experiments but are reliable, scalable, and safely integrated into actual clinical workflows.
A modern healthcare data platform is built to support MLOps from the ground up by providing:
-
A Feature Store: A central library of curated data features, ensuring the same data that trained the model is used for its live predictions.
-
Model Registries: A version control system for your AI models, letting you track, manage, and roll back if needed.
-
Automated Deployment Pipelines: A smooth, automated pathway to move models from development into the live production environment.
-
Continuous Monitoring: Dashboards that track model performance in real time, watching for things like data drift and automatically flagging when a model needs retraining.
This kind of structure isn't optional; it's essential for running AI safely and effectively in a field where mistakes have real consequences. Putting this rigor into practice is why we combine our AI development services with a proven AI transformation framework, ensuring that innovation is backed by operational excellence.
Market Growth Reflects the AI Imperative
This intense focus on AI-driven insights and personalized patient care is fueling explosive market growth. Projections show the healthcare customer data platform segment expanding from USD 0.83 billion in 2026 to an incredible USD 2.72 billion by 2031; that's a compound annual growth rate of 26.92%.
It's no surprise that cloud deployments made up 30.22% of the market back in 2025, a share that continues to grow because AI workloads demand massive computational power. You can dig deeper into these numbers in the full market analysis from Mordor Intelligence. The trend is clear: organizations that get their data strategy right are the ones poised to properly implement AI for your business and define the future of healthcare.
Your Roadmap for Platform Implementation and Migration
Building a modern healthcare data platform isn't a weekend project; it’s a fundamental shift in how your organization operates. Trying to replace everything at once, the classic "big bang" approach, is a surefire way to burn through your budget and frustrate everyone involved.
A much smarter path is a phased, agile roadmap. This breaks the entire initiative into manageable, value-driven stages. You get wins on the board early, which builds the momentum you need to see the project through. It all starts with a clear-headed strategy, mapping your organization's goals to the technical reality with the help of experts in digital transformation consulting.
Stage 1: Discovery and Strategy
Before anyone writes a single line of code, you have to know where you're going. This first stage is all about getting business leaders, clinicians, and your tech team in the same room to turn a vague idea like "modernizing our data" into a concrete set of objectives.
Here’s what that looks like in practice:
-
Defining Business Goals: What problem keeps you up at night? Are you trying to slash patient readmission rates, finally get a handle on operating room schedules, or give your researchers faster access to clinical trial data? Get specific.
-
Identifying High-Value Use Cases: Don't try to boil the ocean. Pinpoint one or two initial projects that promise the biggest impact for the least amount of complexity. A real-time dashboard for the ER to track wait times is a perfect example; it’s visible, valuable, and achievable.
-
Assessing Legacy Systems: You need to take a full inventory of your current data sources. Document their formats, how to access them (or the challenges in doing so), and who relies on them daily.
This foundational work ensures your engineering efforts are always tied to solving real-world problems and delivering a return on investment you can actually measure.
Stage 2: Phased Implementation and Migration
With a clear use case in your sights, you can finally start building. The key here is to start small and prove the concept. Your first goal is a Minimum Viable Platform (MVP) that delivers on that initial high-value project. This might mean only pulling data from two or three core systems to power a single, critical analytics dashboard.
Moving data off legacy systems without causing chaos requires a careful, methodical plan. One of the most effective strategies is the strangler fig pattern. Imagine a vine slowly growing around an old tree. You build your new, modern services around the edges of the old system, gradually peeling off functionality and redirecting users until the legacy application can be safely retired. It completely avoids the immense risk of a "flip the switch" cutover. As we've detailed in our guide on navigating the complexities of healthcare cloud migration, this kind of thoughtful transition is what separates successful projects from failed ones.
An agile, iterative process is your most powerful tool. When you deliver a functional piece of the platform in weeks instead of years, you build trust, keep stakeholders invested, and create a tight feedback loop that makes the final product infinitely better.
Stage 3: Scale and Optimize
Once your MVP is running and people are genuinely using it, you’re ready to scale. This is where you begin connecting more data sources, onboarding more departments, and tackling the next set of use cases on your list.
The lessons you learned building the MVP will be your guide, helping you expand the platform more efficiently. This stage is also about continuous optimization. You’ll be fine-tuning for performance, keeping an eye on costs, and hardening your security posture as you grow.
This entire process depends on rock-solid technical execution from day one. It's why partnering with a team that has deep experience in custom software development is so important. They bring the engineering discipline needed to build a platform that is secure, scalable, and ready for whatever comes next. The results speak for themselves, as our client cases show what’s possible when a great data strategy is brought to life.
Frequently Asked Questions
When you're diving into the world of healthcare data platform engineering, a lot of questions come up. We get it. Here are some of the most common ones we hear, with straightforward answers from our experience in the field.
What’s the Real Difference Between a Data Warehouse and a Data Lake?
Think of a data warehouse like a perfectly organized pharmacy. Every piece of data is structured, cleaned, and neatly labeled for a specific purpose, like generating a report or running a business intelligence dashboard. It’s all about having processed information ready for known questions.
A data lake, on the other hand, is more like a massive, uncatalogued research archive. It holds absolutely everything – raw, unstructured notes alongside structured files. This massive pool of data is perfect for machine learning and deep analysis, where you don't even know what questions you need to ask yet. A modern, high-functioning platform almost always uses a hybrid data lakehouse model that combines the best of both.
How Long Does It Actually Take to Build One of These Platforms?
That’s the million-dollar question, and the honest answer is: it depends. The scope and complexity of your goals are the biggest factors, which is why we always champion a phased approach.
You can get a foundational Minimum Viable Platform (MVP) up and running in 4-6 months. The key is to focus on a single, high-impact use case to prove value and build momentum. From there, building out a full-scale, enterprise-wide platform that pulls in every data source and replaces old systems is a much bigger undertaking, typically taking 12-24 months or more.
The big takeaway here is to avoid a "big bang" launch at all costs. An iterative rollout delivers value faster, lets you adjust on the fly, and makes sure the platform actually solves the problems your team is facing. This is a core principle of good healthcare data platform engineering.
Is FHIR the Only Interoperability Standard I Need to Worry About?
Not by a long shot. While FHIR (Fast Healthcare Interoperability Resources) gets most of the attention as the modern, API-friendly standard, it’s not the only game in town. The reality is that most hospitals still run on older workhorses like HL7v2 for critical internal messaging.
A truly effective data platform has to be bilingual. It must handle the legacy HL7v2 feeds from your on-premise systems just as easily as it communicates with new cloud apps and mobile tools using FHIR. This dual capability is what makes a platform resilient and future-proof, though FHIR's flexibility and web-native design make it the clear path forward for any new development.
At Bridge Global, we know that building a great healthcare data platform is about more than just technology; it requires a deep understanding of compliance, security, and the real-world needs of clinicians. As a dedicated healthtech software development partner, we work with organizations to build secure, scalable, and AI-ready data solutions that turn information into life-saving insights.
About Stephanie Cornelissen
Stephanie Cornelissen is a Technical Solutions Consultant with strong experience helping organizations navigate complex digital change. She works closely with teams to align business goals with practical, scalable technology solutions. With expertise in system architecture, integrations, and emerging technologies, she focuses on solving real-world problems through thoughtful execution. She enjoys working where technology meets business strategy and measurable growth.
View all posts by Stephanie Cornelissen →