


AI-Powered Patient Triage Systems: An Implementation Guide
A triage model that beats conventional scoring on hospital admission, ICU admission, and mortality prediction changes the conversation from workflow optimization to clinical strategy. A 2026 scoping review found that machine learning models consistently outperformed conventional triage systems on those critical outcomes, which is exactly why AI triage now belongs on a CTO agenda, not in an innovation sandbox (2026 scoping review summary).
Most hospitals don't need another demo. They need a reliable intake layer that helps clinicians act sooner, route patients better, and reduce the noise that crushes frontline teams. If you're also looking at workforce pressure through that lens, this roundup of solutions for clinician burnout is worth reviewing alongside any triage initiative.
The hard part isn't deciding whether AI-powered patient triage systems matter. It's deciding how to implement one without creating a new safety problem, a brittle integration mess, or a budget line item that keeps expanding long after go-live.
Why AI Triage Is Redefining Patient Intake
Emergency intake has always been a race against incomplete information. A patient arrives with fragmentary symptoms, staff are under pressure, and every manual handoff adds delay and inconsistency. AI triage matters because it changes that first decision point.
The clinical argument is already strong. That same 2026 review concluded that machine learning models showed superior discrimination over conventional triage systems for critical outcomes, including admission, ICU escalation, and mortality prediction. For hospital leaders, that means AI triage is no longer a speculative add-on. It's a practical way to improve decision quality at the front door of care.
Intake is now a systems problem
Patient intake isn't just a nursing workflow. It's an enterprise coordination problem involving staffing, bed management, documentation, and downstream resource allocation. When triage is inconsistent, the entire hospital absorbs the impact.
Three things make AI triage strategically important:
-
It improves early prioritization: The first routing decision gets sharper when the system evaluates patterns humans may miss under pressure.
-
It supports throughput: Better prioritization reduces avoidable friction in queues, reassessment, and escalation.
-
It helps standardize decisions: Hospitals don't want triage quality to vary by shift, fatigue level, or local staffing strain.
Practical rule: Treat triage AI as clinical infrastructure, not as a front-end chatbot project.
The real shift is operational confidence
The value isn't just speed. The value is confidence that the right patient gets attention first, with a more consistent rationale behind that decision. That matters in emergency departments, urgent care, telehealth intake, and any digital front door where demand is volatile.
Leaders who frame AI-powered patient triage systems purely as efficiency tools undersell the opportunity. The bigger win is a stronger intake layer that supports safer escalation, cleaner handoffs, and better use of scarce clinical time.
Understanding the Core Architecture of AI Triage
A good AI triage system works like a disciplined digital front door. It takes messy, mixed-format patient information, turns it into a usable risk picture, and pushes that output into live clinical workflow without forcing staff into another disconnected interface.
The architecture is usually easier to evaluate if you split it into three layers: intake, prediction, and operational delivery.
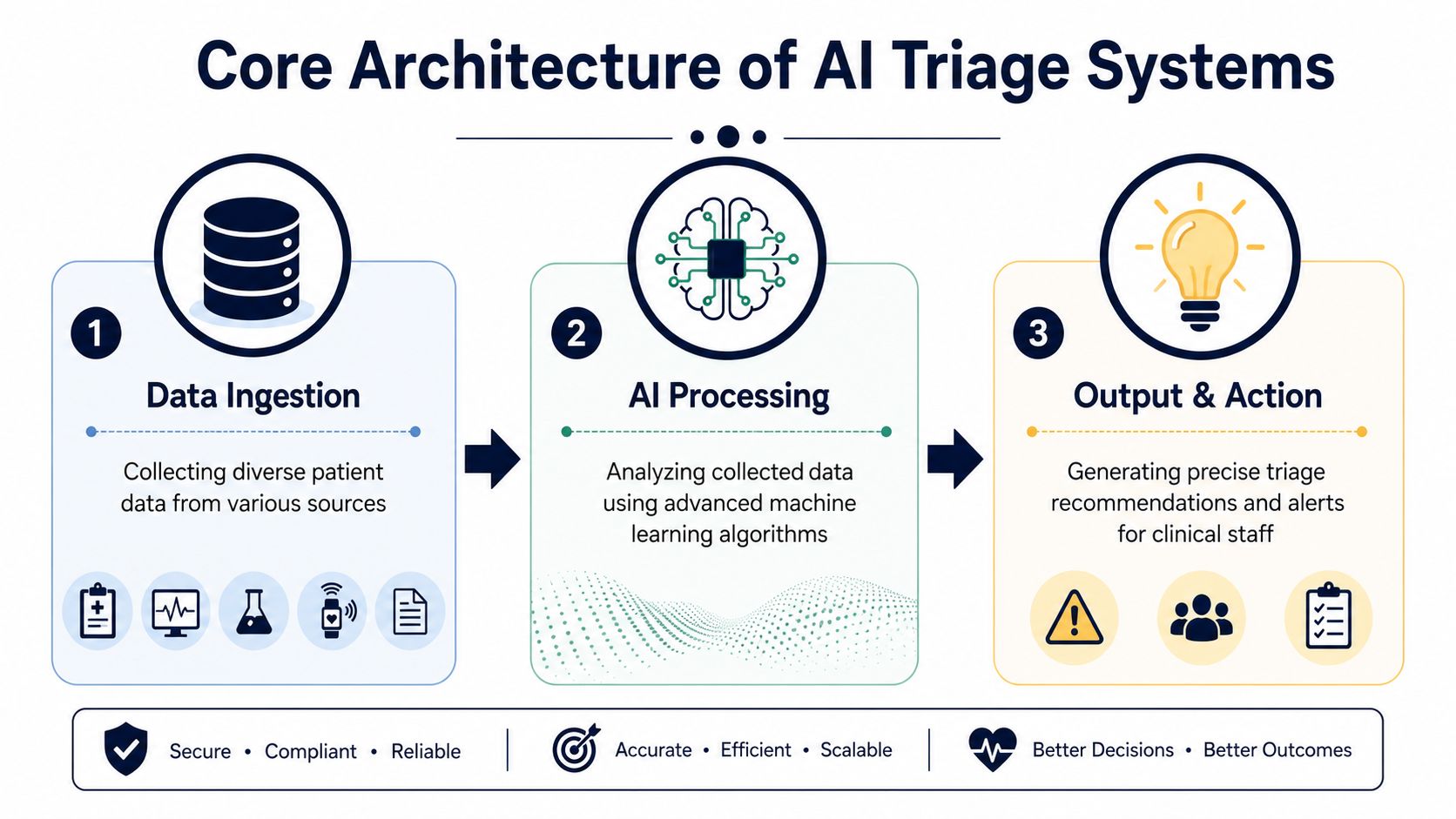
Data ingestion and clinical context
The first layer collects both structured and unstructured data. That includes vitals, labs, medication history, prior encounters, and the patient's own symptom narrative. This is where natural language processing starts to matter. A system that only reads checkboxes is weak. A system that can interpret free-text complaints is more useful in real intake conditions.
High-fidelity systems integrate over 50 distinct clinical data points and process them in approximately 180 seconds using tools such as XGBoost and neural network algorithms to generate a risk assessment aligned closely with expert clinical judgment. That combination of real-time vitals, NLP-parsed symptoms, and EHR data is the technical baseline you should expect in a serious platform.
If you want a simple way to explain this internally, compare it to other clinically sensitive AI workflows that combine signal extraction with domain-specific interpretation.
Prediction engines and model behavior
The second layer is the acuity engine, which scores risk, estimates urgency, and forecasts likely needs such as admission or intervention. Vendors often talk about “AI” in vague terms. Don't accept that. Ask which model classes they use, what features feed the model, how they manage missingness, and how often they validate performance after deployment.
A mature architecture usually includes:
-
Feature engineering: Normalizing vitals, encounter history, and narrative data into model-ready inputs.
-
Model orchestration: Running one or more predictive models for urgency, admission likelihood, or intervention need.
-
Explainability output: Returning a rationale clinicians can interpret quickly, not just a color-coded score.
For teams evaluating build options, deep machine learning engineering capability matters most. The difference between a demo and a deployable system usually shows up in feature handling, drift monitoring, and explainability.
Output and workflow integration
The final layer determines whether the product succeeds. If the output lives in a side dashboard that no one checks, the architecture failed. Triage recommendations need to surface where clinicians already work, with a clear action path.
Here's the minimum you should expect from output design:
| Component | What it should do |
|---|---|
| Risk score | Show patient acuity in a way clinicians can review quickly |
| Suggested action | Recommend next routing step, escalation path, or review urgency |
| Confidence signals | Indicate why the model produced that result |
| Workflow trigger | Push alerts or queue changes into live operations |
A triage model is only useful when its output changes an actual decision in an actual workflow.
If you're assessing vendors or internal prototypes, focus less on interface polish and more on whether the architecture can survive real data quality issues, real clinical ambiguity, and real integration constraints. That's where AI-powered patient triage systems either prove their value or collapse under production conditions.
Navigating Clinical and Regulatory Requirements
A triage model that improves throughput but creates patient-safety risk, bias exposure, or audit failures is a bad investment. CTOs should treat clinical assurance, regulatory control, and equity testing as deployment gates, not cleanup work after procurement.

Validation has to reflect clinical reality
Vendor accuracy claims are a weak filter. Ask whether the model was validated on your care setting, your patient mix, and your operational constraints. Retrospective performance alone is not enough. You need evidence that the system behaves predictably under live workflow pressure, incomplete data, and clinician overrides.
Set a higher bar from the start:
-
Clinical accountability stays with the care team: AI can support prioritization, but it cannot obscure who owns the decision.
-
Recommendations must map to accepted clinical logic: If the output cannot be defended in chart review or incident review, do not deploy it.
-
Post-launch surveillance is part of the product: Monitor drift, false reassurance, missed escalations, and override patterns after go-live.
Teams that need a clearer view of approval, security, and documentation requirements should review this whitepaper on AI regulatory compliance and security for medtech.
The equity blind spot is a patient-safety issue
Many hospital AI programs still review fairness late, after the model already looks operationally attractive. That is the wrong order. In triage, uneven sensitivity across age, ethnicity, language, disability status, or socioeconomic groups can push the wrong patients down the queue.
A published JMIR equity analysis highlights how subgroup performance gaps in AI triage can become clinically meaningful. Procurement teams should stop accepting aggregate AUC or average sensitivity as proof of safety. Require subgroup testing, threshold review, and monitoring plans before pilot approval.
If a vendor cannot show how the model underperforms, you do not have enough evidence to put it in production.
What responsible governance looks like
Strong governance is cross-functional and boring by design. That is a strength. Clinical leadership, compliance, legal, security, data science, and operations should agree on approval criteria before the first pilot patient is assessed.
Use four controls as a minimum:
-
Clinical use-case approval
Confirm the system is being used for decision support in a clearly defined workflow, with known escalation boundaries. -
Subgroup performance review
Test demographic performance before rollout and repeat that analysis after major model, workflow, or population changes. -
Override and escalation design
Give clinicians a fast way to challenge, bypass, or escalate an AI recommendation, and log what happened. -
Audit-ready traceability
Record inputs, recommendations, overrides, timestamps, downstream actions, and outcomes so incident review is possible.
Budget for the operating burden as well. Governance adds cost through validation work, documentation, security review, incident handling, retraining oversight, and periodic reapproval. That is part of the total cost of ownership. Leaders who ignore it usually underestimate both implementation time and long-term ROI.
A Practical Implementation Roadmap
Hospitals rarely struggle with the model first. They struggle with ownership, workflow fit, and the hidden operating cost of keeping triage safe after go-live.
That is why a good implementation plan starts with one hard question. Where, exactly, does AI improve intake without adding clinical risk, staff friction, or equity gaps?
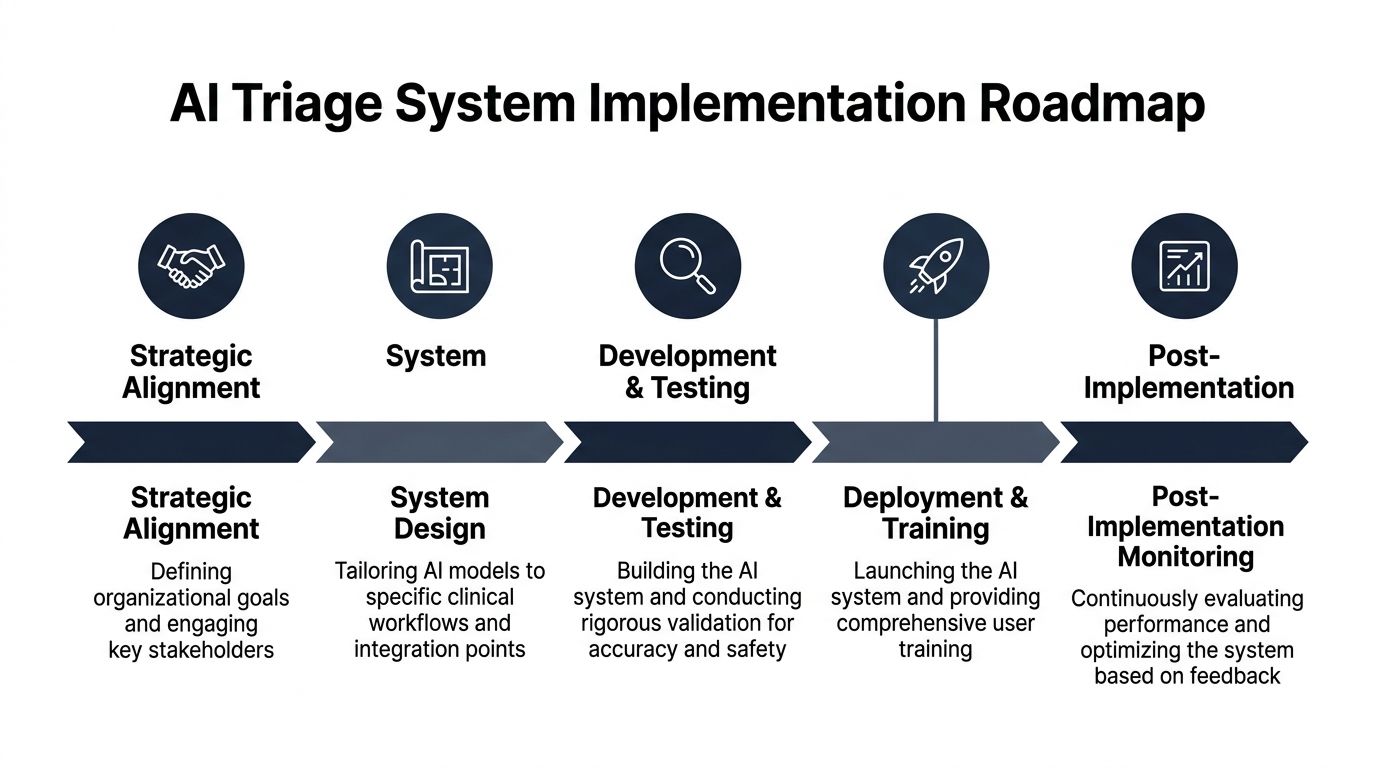
Start with the intake decision, not the vendor demo
Define the intake moment before you compare products or approve a build. Emergency department walk-in triage, urgent care routing, nurse call-center prioritization, and telehealth pre-assessment are different operating problems. They use different data, demand different response times, and carry different escalation risk.
Set four decisions early:
-
The workflow in scope
-
The clinician or team is accountable for the final decision
-
The action the system should trigger
-
The business and clinical outcomes that justify deployment
Use a formal AI transformation framework for healthcare implementation if your organization tends to run strategy, integration, validation, and change management as separate projects. In triage, fragmented delivery creates delays, weak accountability, and expensive rework.
Do not start with a broad enterprise rollout. Start where intake friction is high, decision logic is repetitive, and clinical leadership will actively review the results.
Design the technical plan around production reality
A triage system only matters if it works inside the live care pathway. Integration is the implementation risk that decides whether the tool becomes part of operations or sits unused beside them.
Your architecture should cover three things from the start. First, inbound data mapping across symptoms, vitals, encounter history, and unstructured notes. Second, standards and terminology alignment across HL7, FHIR, event triggers, and local coding practices. Third, output placement inside the systems clinicians already use, including queue prioritization, alerts, and escalation paths.
Do not accept abstract claims about interoperability. Ask to see the interface design, the failure states, the latency assumptions, and the support model for interface changes after launch.
Build the pilot to expose operational risk early
A credible pilot is narrow, instrumented, and difficult to game. Pick one setting. Use one workflow. Require staff training, documented overrides, and a clear review cadence.
That discipline matters for more than safety. It is also how you find the equity blind spot before it becomes a production issue. If the pilot does not test performance across relevant patient subgroups, you are not validating triage. You are validating an average.
Use this sequence:
| Phase | What to do |
|---|---|
| Alignment | Confirm the workflow, accountable owners, escalation rules, and approval criteria |
| Design | Define inputs, recommendation classes, user interface placement, and override handling |
| Validation | Test against local cases, review subgroup behavior, and document failure patterns |
| Deployment | Launch with training, audit logging, support coverage, and issue response procedures |
| Stabilization | Review exceptions, workflow delays, clinician adoption, and model-related incidents weekly |
One more rule. Budget for the work after deployment before you approve the pilot. Model review, incident handling, retraining oversight, interface maintenance, clinician refresh training, and periodic governance checks are part of the total cost of ownership. Leaders who ignore that usually overestimate ROI and underestimate the time to scale.
For product teams building for providers, the same rule applies. A triage feature succeeds when it fits the care workflow, the operating model, and the hospital's risk tolerance. Model novelty does not drive adoption. Implementation quality does.
Evaluating Success and Monitoring Performance
A triage model that looks accurate in validation can still fail in production. The gap usually shows up in workflow friction, subgroup bias, weak override review, or silent performance drift. Measure all four from day one.
Start with clinical performance that holds up under local conditions
Published evidence sets a useful floor, not a guarantee. A Cureus systematic review found triage models with AUROC values from 0.82 to 0.94 and sensitivities often above 0.75 across studies. Use those figures to scrutinize vendor claims and internal validation results. Do not treat them as proof that your deployment will perform the same way in your patient population.
Your production scorecard should track:
-
Discrimination quality: AUROC, sensitivity, and calibration in the live setting
-
Under-triage risk: Cases where the model assigned a lower urgency than the eventual clinical outcome justified
-
Override patterns: Rejection rates by clinician role, site, shift, and reason code
-
Subgroup performance: Results across age, ethnicity, language, disability, payer mix, deprivation, and other locally relevant variables
Many teams overlook the equity blind spot. Average performance can look acceptable while specific patient groups absorb most of the failure risk. If you do not monitor subgroup error rates, you are not managing triage risk. You are hiding it inside an aggregate.
Measure workflow impact separately from model quality
Clinical accuracy alone does not justify a rollout. Hospital leadership needs proof that the system improves intake operations without adding a new burden to already constrained teams.
Track a short set of operational indicators that tie directly to service performance:
-
Time to appropriate routing: Whether higher-risk patients reach the right care pathway faster
-
Rework volume: Whether staff spend less time reassessing unclear or misdirected cases
-
Documentation usability: Whether intake notes are easier for downstream clinicians to act on
-
Capacity visibility: Whether teams can anticipate escalations, admissions, or urgent reviews earlier
Keep the dashboard tight. If every metric is green, none of them drives action.
Build a review model, not just a dashboard
Dashboards do not govern systems. People do. Assign named owners for clinical safety, operations, fairness review, and technical performance. Set trigger thresholds that force action, such as sustained drops in sensitivity, rising override rates for a specific site, or worsening results for a protected subgroup.
Use separate cadences for separate problems. Weekly reviews should focus on incidents, overrides, and workflow bottlenecks. Monthly reviews should examine trend lines, calibration, and service impact. Fairness audits need their own schedule and documented remediation path.
If you are building a platform-based product, architecture choices also affect monitoring quality. Multi-tenant reporting, auditability, and release controls matter as much as model logic. Teams with a broader SaaS product development roadmap should design for tenant-level monitoring early, or they will end up rebuilding reporting and governance later at a much higher cost.
Calculating ROI and Choosing the Right Partner
A triage system that looks affordable in procurement can become expensive within a year if you ignore integration, governance, and equity monitoring. CTOs should treat AI triage as an operating model decision, not a software line item.
The budget question is simple. What will it cost to run this safely, fairly, and reliably at scale?
ROI only counts when TCO reflects reality
License fees and pilot savings are the easy part. The true cost sits in the work around the model. Integration with the EHR, identity and access controls, clinician training, audit logging, incident review, model updates, and subgroup performance checks all add cost. They also determine whether the system survives compliance review and daily clinical use.
The Equity Blind Spot belongs in the financial model, not in a footnote. If the model performs worse for patients with limited English proficiency, lower digital literacy, or underrepresented clinical histories, your team will pay for it later through rework, overrides, safety reviews, and trust erosion. A cheaper deployment that creates uneven performance is not cheaper.
Your ROI model should account for five cost layers:
-
Acquisition or build cost
-
Integration across EHR, scheduling, messaging, and identity systems
-
Clinical validation, version control, and update cycles
-
Fairness review, safety oversight, and audit support
-
Training, workflow redesign, and support operations
Then measure returns in operational and financial terms that leadership will accept. Reduced misrouting, lower avoidable escalation, faster time to clinical decision, better staff utilization, and improved intake consistency are usually more credible than broad labor-saving claims.
Choose build, buy, or hybrid based on control
Buy a product if your hospital needs a narrow use case, lives quickly, and can accept the vendor's workflow assumptions.
Build if triage logic, orchestration, and downstream decision support will become a strategic capability across service lines.
Use a hybrid model if you want vendor speed for the core engine but need your own integration layer, reporting, routing rules, or governance controls.
| Path | Best fit |
|---|---|
| Buy | Fast deployment, standard workflows, lower internal engineering demand |
| Build | High workflow control, stronger IP ownership, tighter fit with internal platforms |
| Hybrid | Faster launch with custom orchestration, reporting, and integration control |
Be blunt about your internal maturity. If your team cannot support model governance, release management, and clinical workflow configuration, a full custom build will drag on and underdeliver.
Partner selection should focus on delivery risk
Do not choose a partner because they have a polished demo. Choose them because they can ship into a regulated hospital environment without creating operational debt.
Review a potential healthtech software development partner for evidence in four areas. First, healthcare workflow depth. They should understand triage, escalation, handoff, and documentation requirements well enough to challenge weak assumptions. Second, technical integration. They must speak clearly about EHR interoperability, audit trails, role-based access, and deployment constraints. Third, AI operations. Ask how they handle validation, rollback, drift response, and release approval. Fourth, fairness discipline. They should have a concrete method for subgroup testing, remediation, and ongoing review.
If you need a quick filter, ask three questions: who owns clinical safety after go-live, how is subgroup performance measured and reported, and what operating costs should we expect in year two, after the pilot team is gone?
For AI capability specifically, assess their enterprise AI solutions and ask for relevant client cases. If the answers stay at the level of model accuracy and implementation speed, keep looking. The right partner can explain the full cost structure, the equity risks, and the workflow tradeoffs in plain terms.
Frequently Asked Questions About AI Triage Systems
Can we start with a pilot instead of a hospital-wide rollout?
Yes. Start with a pilot.
Choose one intake pathway with high volume, clear pain, and a clinical lead who will hold the system to account. Good starting points include urgent care intake, nurse advice lines, or specialty referral screening. Set hard boundaries before launch. Define which decisions the model can support, when staff must override it, how exceptions are escalated, and what safety review happens each week.
A pilot should answer three questions: does it reduce intake delay, does it fit clinician workflow, and does performance hold across patient subgroups, not just the average patient population? If you do not test for the equity blind spot early, you risk scaling a faster system that performs worse for underserved groups.
How much staff training does an AI triage deployment need?
More than budget owners expect.
Do not treat training as a one-time onboarding session. Clinicians need to know what the model sees, what it cannot infer, how confidence is presented, and when human judgment overrides the recommendation. Operations teams need escalation rules and downtime procedures. IT and informatics teams need enough depth to investigate incidents, support updates, and review audit logs.
Role-based training works best because triage nurses, physicians, access teams, and support staff use the system differently. Build refresh training into go-live plans, especially after model changes or workflow updates.
How do we protect privacy when patient data is feeding an AI model?
Handle privacy as a system design decision.
Decide upfront which data elements enter the model, where processing occurs, how outputs are stored, who can view them, and how long logs are retained. Map those controls to your EHR, identity management, consent model, and vendor agreements. If a supplier cannot explain data flow, auditability, and access controls in plain language, do not move forward.
Security review also needs to cover third-party models, API dependencies, and prompt or input handling if generative AI is involved. The actual risk is rarely the demo. It is the production architecture no one has examined closely enough.
Bridge Global helps healthcare organizations and product teams move from an AI triage concept to compliant delivery with the right mix of strategy, engineering, and integration support. If you’re evaluating AI-powered patient triage systems, planning a pilot, or deciding between build and buy, assess whether your partner can prove clinical workflow fit, fairness testing discipline, and realistic year-two operating costs before you commit.
About Preethi Saro Philip
Preethi Saro Philip is a Post Graduate Research Degree holder in Economics with more than 10 years of experience in writing, editing, research and teaching. She has an intense passion for content crafting and calls herself a ‘wordsmith’. She enjoys writing on wide-ranging topics including business, technology, health & lifestyle, education, environment etc.
View all posts by Preethi Saro Philip →