


Mastering Medical Platform Integration Engineering
A patient books a telehealth follow-up after a hospital stay. Their primary care history sits in one EHR. The specialist documented changes in another system. Imaging lives in a PACS archive. Medication updates are sitting with the pharmacy platform. By the time the clinician opens the chart, the data is technically available, but operationally fragmented.
That’s the reality medical leaders inherit. Not a lack of software, but too many systems that were never engineered to work as one. Medical platform integration engineering is the discipline that turns those disconnected tools into a usable clinical platform. It covers the architecture, mapping, security, testing, and operational controls required to move healthcare data safely between systems and make it usable in workflow.
For startup CTOs, this usually starts as a product problem. For enterprise VPs, it shows up as an operational and risk problem. In practice, it’s both. Teams that treat integration as a side task usually end up paying for it later in delays, brittle interfaces, and compliance exposure. Teams that treat it as a core engineering function build platforms that can scale.
The High Cost of Disconnected Healthcare Data
The cost of disconnected data isn’t abstract. It shows up when a clinician has to verify medications by phone because the latest update hasn’t reached the care platform. It shows up when a billing workflow stalls because diagnosis data was captured in one format and expected in another. It shows up when a patient repeats the same history three times because each provider sees only part of the story.

Why this has become a board-level issue
Healthcare organizations aren’t integrating systems because it sounds modern. They’re doing it because fragmented operations break care continuity and slow revenue flow. The market reflects that urgency. The global healthcare data integration market was valued at USD 1.05 billion in 2022 and is projected to reach USD 3.11 billion by 2030, growing at a CAGR of 14.5%, driven by EHR adoption and the need to consolidate data from multiple sources, according to Grand View Research’s healthcare data integration market analysis.
That growth matters, but the more useful takeaway is what it signals. Buyers are no longer asking whether integration is necessary. They’re asking how to do it without creating a fragile mess of interfaces and exceptions.
What medical platform integration engineering actually means
A lot of articles reduce this topic to standards acronyms. That’s incomplete.
Medical platform integration engineering is the work of deciding:
-
What systems are authoritative for each data domain
-
How data moves between those systems
-
Where transformation happens
-
How identity is reconciled
-
What gets logged, encrypted, retried, quarantined, or rejected
-
How clinicians receive integrated information inside actual workflows
Practical rule: If a platform can exchange data but clinicians still rely on manual reconciliation, the integration is incomplete.
This is why choosing a healthtech software development partner matters less as a staffing decision and more as a systems design decision. The hard part isn’t connecting two endpoints once. The hard part is building an integration model that survives new partners, new data types, audits, product changes, and growth.
The Pillars of Healthcare Interoperability
Most healthcare platforms run into the same misunderstanding early. Teams assume interoperability means picking one standard and implementing it. In reality, healthcare environments usually contain several standards at once, each designed for a different job.
HL7 is the legacy workhorse
HL7 v2 still carries a huge amount of operational traffic across hospitals and clinics. Admission messages, discharge updates, lab notifications, scheduling events, and order flows often move through HL7 feeds. It’s reliable, widely supported, and thoroughly embedded.
But HL7 is also where many projects get into trouble. Two systems can both claim HL7 support and still fail to exchange data cleanly because one uses custom segment structures, local code systems, or different field conventions. That’s why interface success depends less on nominal standard support and more on how carefully the teams map and validate the payloads.
DICOM handles imaging correctly
DICOM sits in a different category. It’s the language of medical imaging and the metadata around it. If your platform touches radiology, cardiology imaging, or diagnostics that involve scans, DICOM isn’t optional.
A common engineering mistake is treating imaging as a file transfer problem. It isn’t. The challenge is preserving image context, study metadata, retrieval patterns, and links back into the clinical workflow. A viewer that loads an image but loses the patient or encounter context doesn’t solve the problem clinicians care about.
FHIR fits modern product delivery
FHIR is what most modern platform teams want because it works more naturally with web and mobile application patterns. It structures healthcare data into resources and exposes them through API-friendly interactions. That makes it a much better fit for patient apps, care coordination tools, partner ecosystems, and analytics pipelines.
That doesn’t mean FHIR replaces everything. In practice, FHIR often sits alongside HL7 and DICOM. Your integration layer may ingest HL7 from a hospital information system, consume DICOM study references from imaging infrastructure, and expose normalized data through FHIR APIs to downstream apps built in custom healthcare software development.
Standards don’t remove engineering complexity. They move complexity into translation, governance, and workflow design.
Where projects actually fail
The biggest failures usually happen in mapping, not transport. Data mapping failures during EHR interoperability are responsible for up to 70% of integration project breakdowns, according to Emorphis Health’s analysis of healthcare integration challenges. When one system uses different terminology, identifiers, or local coding conventions, the result can be incomplete records and a rising clinical error risk.
A practical way to think about the standards stack is this:
| Standard | Best suited for | Common challenge |
|---|---|---|
| HL7 | Operational messaging between existing clinical systems | Heavy customization |
| DICOM | Imaging data and study metadata | Workflow context and retrieval design |
| FHIR | Modern APIs and reusable clinical resources | Governance and consistent resource modeling |
The engineering discipline is knowing when to preserve native formats, when to normalize, and when to expose a cleaner abstraction for downstream systems.
Choosing Your Integration Architecture
Architectural choices create long-term operating conditions. A system that seems fast to launch can become costly to maintain after the third partner integration, and completely unmanageable after the tenth.
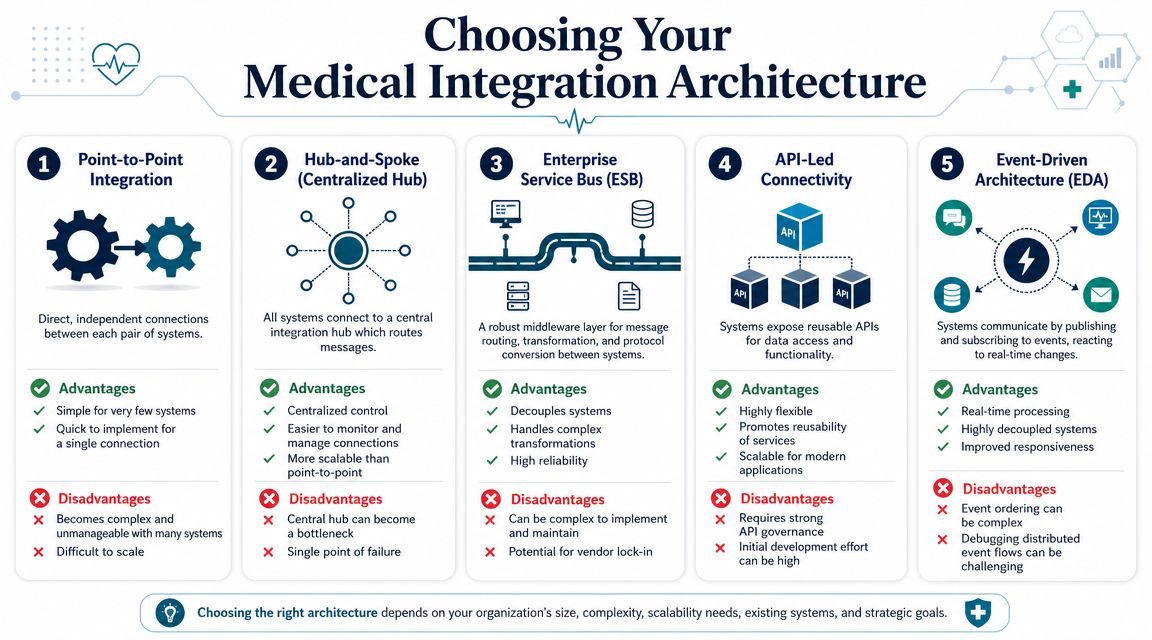
Point-to-point works until it doesn't
Point-to-point integration is exactly what it sounds like. System A connects directly to System B, often with a custom interface built for one exchange. For an early-stage startup with a single payer partner or one lab integration, this can be a reasonable move.
The problem is multiplication. Every new system adds more direct dependencies, more bespoke logic, and more hidden failure paths. Small teams often underestimate how quickly this becomes a maintenance burden.
Hub models improve control but can centralize pain
Hub-and-spoke patterns and ESB-style middleware introduce a central integration layer. This gives teams a place to route, transform, monitor, retry, and govern traffic. For many provider organizations, that's a major step up from interface sprawl.
A well-run hub gives you:
-
Central observability for messages and failures
-
Reusable transformations instead of duplicating logic
-
Policy enforcement around validation and access
-
Cleaner onboarding for additional systems
The trade-off is concentration. If the hub becomes overloaded, poorly governed, or too vendor-specific, it turns into an operational bottleneck.
API-led and event-driven patterns support modern platforms
For product-centric healthtech platforms, API-led connectivity is often the better backbone. Systems expose capabilities through defined APIs. Downstream applications consume those APIs rather than building custom dependencies against internal storage or legacy workflows.
Event-driven design goes one step further. Instead of waiting for scheduled jobs or synchronous requests, systems publish events when clinical or operational changes occur. Subscribers react to those events in near real time. This pattern is particularly useful for care coordination, alerting, telehealth workflows, patient engagement, and analytics pipelines that need timely updates.
Architect's note: Use synchronous APIs for actions that need immediate confirmation. Use events for state changes that multiple systems should react to independently.
A practical comparison
| Architecture | Best fit | What usually goes wrong |
|---|---|---|
| Point-to-point | One or two limited integrations | Hidden complexity as partners grow |
| Hub-and-spoke | Organizations needing central control | Hub overload and weak governance |
| ESB | Complex transformations across mixed protocols | Heavy administration and lock-in risk |
| API-led | Product platforms with reusable services | Inconsistent API design across teams |
| Event-driven | Real-time, decoupled workflows | Debugging distributed behavior |
A lot of teams don't need to choose one pattern exclusively. The stronger designs are usually hybrid. An enterprise may keep an interface engine for legacy HL7 traffic, expose normalized FHIR APIs for product apps, and publish events for notifications or operational triggers.
When evaluating tools, the key is to align the pattern with operating reality. The integration catalog, adapters, and interface strategy outlined in healthcare tools and integrations are useful examples of how these pieces fit together at the platform level.
The selection criteria that matter
The architecture should match your actual constraints:
-
Legacy footprint: More HL7-heavy estates usually need stronger mediation and transformation.
-
Product velocity: Faster product cycles benefit from API reuse and cleaner service boundaries.
-
Real-time needs: If timing affects care or operations, event patterns become much more important.
-
Governance maturity: API-first only works when versioning, ownership, and contracts are managed well.
If you are building for long-term interoperability rather than quick interface wins, disciplined product engineering services deliver significant value.
Securing the Data Flow From End to End
Healthcare integration projects often fail security reviews for a simple reason. The team treated security as a perimeter concern instead of a data flow concern. Once data moves across EHRs, imaging systems, patient apps, partner APIs, warehouses, and analytics pipelines, the attack surface expands with every connection.

Security controls have to follow the message
A compliant architecture doesn't stop at encrypting a database. You need controls around identity, authorization, message integrity, logging, secret handling, queue security, and auditability across every hop.
That becomes harder when platforms have to manage multiple protocols and older systems. Advanced healthcare analytics platforms can achieve 98.7% effectiveness in threat detection and manage an average of eight different HL7 interfaces, according to the IJAEM paper on healthcare analytics platform engineering. That combination matters. Security posture and integration complexity rise together.
What secure medical platform integration engineering looks like
The strongest implementations usually include a consistent set of controls:
-
Authentication that matches the integration type: OAuth 2.0 and SMART on FHIR are strong fits for modern application access. Service-to-service exchanges may need token brokerage and short-lived credentials.
-
Fine-grained authorization: Don't hand downstream systems blanket access to broad clinical records when the workflow only requires a narrow dataset.
-
Immutable audit trails: Every access, transformation, push, retry, and exception should be attributable.
-
Transport and payload protection: Encryption in transit is table stakes. Sensitive payload handling, field filtering, and secure storage of transient data matter just as much.
-
Failure isolation: If a downstream system misbehaves, queues and retry logic should protect upstream clinical workflows from cascading errors.
Security review should start at the architecture design, not the week before go-live.
Testing has to be continuous, not ceremonial
A surprising number of teams document controls well and still ship exploitable integrations because they don't test the running system the way an attacker or misconfiguration would affect it. Secure design needs active verification through interface testing, dependency review, access-path analysis, and workflow-specific abuse cases.
For teams building healthcare integrations, the e2eAgent.io guide to vulnerability hunting is a useful operational reference because it frames security testing as part of software quality, not a separate compliance checkbox.
This is also where specialized cyber compliance solutions become practical, not abstract. You need repeatable controls that survive product releases, vendor changes, and audits. If the platform can't prove who accessed what, when data moved, how an exception was handled, and whether a policy was held, then the architecture isn't production-ready.
Engineering for AI and Advanced Analytics
Most healthcare AI programs don't fail because the model is weak. They fail because the surrounding platform can't deliver clean, governed, timely data into the model and return usable output into the workflow.

AI depends on integration discipline
Clinical AI needs more than data access. It needs identity resolution, stable schemas, reproducible pipelines, permission boundaries, and delivery patterns that fit the clinician workflow. If your integration layer produces inconsistent records or undocumented transformations, your model pipeline inherits those defects.
That's why a systems engineering approach matters. A framework for AI and ML integration in healthcare can mitigate failure rates of 40-60% by structuring projects into phases, and platform engineering has enabled 43% of organizations to accelerate deployments by 40% while ensuring HIPAA compliance, as described in the PMC systems engineering framework for AI and ML integration in healthcare.
The pattern that works in production
In practice, useful healthcare AI usually follows a sequence like this:
-
Normalize and govern the source data across clinical and operational systems.
-
Create reusable pipelines for feature extraction, model input preparation, and validation.
-
Expose inference cleanly through APIs or event-driven services.
-
Embed outputs in workflow where clinicians or operations teams can act on them.
-
Monitor drift and downstream behavior after launch.
The weak version of this pattern is a notebook connected to ad hoc exports. The strong version is a platform capability.
What to architect before training starts
Teams move faster when they answer these questions early:
-
Where will model-ready data live?
-
Which system owns labels and outcome definitions?
-
How will predictions return to the user-facing platform?
-
What happens when upstream clinical data changes shape?
-
Who signs off on model access and auditability?
One practical option is to treat AI as part of the broader integration estate rather than a separate workstream. That's where AI development services, an AI transformation framework, and a shared data and AI engineering capability can fit. The important point isn't the label. It's that AI only becomes reliable when the platform underneath it is engineered with the same rigor as the application layer.
If your AI pipeline requires manual CSV repair before every release, you don't have an AI platform. You have a recurring integration defect.
For executives exploring AI for your business, this is the distinction that matters most.
Real-World Implementation and Risk Mitigation
At 2 a.m., an interface can look healthy while the care workflow is already broken. Messages are flowing, acknowledgments are green, and yet orders are landing in the wrong queue, amended results are not reaching the right team, or a patient merge has split the record history in downstream systems. That gap between transport success and operational success is where healthcare integration programs usually fail.
The engineering work that prevents this starts well before production. It starts with a discovery that is detailed enough to expose business ambiguity, not just technical dependencies.
Start with a hard discovery phase
A useful discovery phase does more than list systems and vendors. It identifies where data is created, where it is transformed, which local code sets exist, how downtime is handled, and which workflows carry patient safety or revenue-cycle risk. In practice, that means tracing the path of a clinical event across departments and systems until ownership is unambiguous.
Discovery should usually produce four artifacts:
-
Source-of-truth mapping for patient, encounter, orders, results, billing, and documents
-
Interface inventory across HL7, FHIR, flat files, DICOM, SFTP feeds, and proprietary APIs
-
Operational dependency mapping for scheduling cutoffs, care-team notifications, billing handoffs, and exception queues
-
Governance decisions on data ownership, terminology, reconciliation rules, and escalation paths
This is often the point where a program finds its real blocker. The interface is technically feasible, but the organization has never agreed on which system owns the final diagnosis, who resolves identity conflicts, or how corrected data should propagate.
Roll out in phases that reduce blast radius
Big-bang cutovers create unnecessary risk in healthcare. A phased rollout gives the team time to validate mappings against live operational behavior, adjust retry logic, and prove that support teams can run the platform after go-live.
A practical sequence looks like this:
| Phase | Focus | Success signal |
|---|---|---|
| Assessment | Systems, workflows, risks, ownership | Shared integration blueprint |
| Pilot | One constrained workflow | Stable exchange and user acceptance |
| Expansion | Additional systems and use cases | Reusable patterns and fewer exceptions |
| Operationalization | Monitoring, support, governance | Predictable releases and audit readiness |
The right pilot is narrow but meaningful. A single departmental workflow with clear downstream consequences works better than a low-value interface that never tests the operating model.
Test workflows, failure states, and recovery paths
Interface validation alone is too shallow for medical platforms. A message can pass schema checks and still create clinical or financial defects. Test plans need to cover what users and operations teams depend on.
That includes questions such as:
-
Does a lab result reach the correct work queue within the expected time window?
-
Does an amended diagnosis update downstream billing and reporting correctly?
-
Does a patient merge preserve historical context across connected systems?
-
Does a failed outbound push create an alert, a retry, and a human review path?
-
Does downtime processing replay events in the right order once service resumes?
Release engineering matters here. CI/CD is not at odds with regulated delivery if the pipeline records approvals, test evidence, deployment history, and rollback steps. Good software engineering improves healthcare integration because it makes change traceable and repeatable.
A passing interface test only proves a message was accepted. It does not prove that the workflow remained safe.
Watch platform economics and operating ownership
Technical teams usually see interface count, throughput, latency, and error rates first. Executives ask a different set of questions. What does this platform cost to run? Who owns mappings after implementation? How much of the estate depends on one vendor runtime? What happens to delivery speed when every new connection requires specialist intervention?
As discussed in HealthTech Magazine’s analysis of platform engineering in healthcare, healthcare leaders are increasingly interested in platform engineering, but they still need a credible operating and cost model. If those answers are vague, budget support weakens fast.
This is an architecture decision as much as a financial one. Teams should separate durable assets from tool-specific configuration wherever possible. Keep interface contracts documented. Keep canonical models understandable by people outside the implementation vendor. Keep monitoring rules and support procedures under your control.
Treat vendor lock-in as an engineering risk
Vendor lock-in rarely starts at procurement. It starts when transformations, routing rules, alert logic, and operational knowledge live only inside one proprietary platform, and one small delivery team knows how it works.
The alternative is not avoiding commercial tools. The better path is to use them selectively and design for portability where it matters. Put business rules in places your team can inspect. Version your mappings. Document integration contracts. Make sure a new support team can trace a failed transaction without reverse-engineering the whole stack.
For organizations that need outside delivery support, a partner such as Bridge Global can contribute through client cases and domain-specific healthcare delivery support. The useful measure is simple. At the end of the program, your team should inherit an integration estate that it can operate, extend, and audit without depending on tribal knowledge.
Building Your Connected Health Ecosystem
Medical platform integration engineering isn’t a side layer under the product. It is the product foundation for any healthcare organization that depends on connected workflows, partner data exchange, or AI-enabled decision support.
The strategic choices are clear. Use standards appropriately, but don’t confuse standards with architecture. Choose an integration pattern that matches your operating model, not just your current backlog. Engineer security into the movement of data, not only the places where data rests. Treat testing as workflow validation, not message transport validation. Build for future analytics only after the integration backbone is stable enough to support them.
The payoff is practical. Clinicians get a better context. Product teams ship fewer brittle interfaces. Operations teams gain visibility. Compliance teams get traceability. Leadership gets a platform that can absorb new systems without rebuilding the whole estate.
If your roadmap includes EHR connectivity, partner APIs, imaging workflows, care coordination, or AI-enabled services, a dedicated development team with healthcare integration experience can reduce risk significantly. The right team doesn’t just connect systems. It leaves you with an architecture that your organization can operate confidently.
Frequently Asked Questions
What’s the difference between interoperability and integration?
A startup can have every required connection in place and still fail at real interoperability. The API calls succeed. Messages arrive. Clinicians still do not trust the record because medications map incorrectly, patient identity is inconsistent, or the receiving workflow cannot use the data at the moment it matters.
Interoperability is the operating result. Systems exchange data in a form that the other side can interpret and use safely. Integration is the engineering discipline that produces that result through interface design, terminology mapping, identity resolution, workflow alignment, and validation in production-like conditions.
That distinction matters during planning. Teams that budget only for connectivity usually discover late that the harder work sits in data semantics and operational behavior.
How long does a typical medical integration project take?
The honest answer is that timelines are set by risk, not by message format.
A straightforward connection to a well-documented modern API can move quickly. A program that involves a legacy EHR, security review, identity matching, partner certification, and end-to-end workflow testing usually takes much longer. The delay rarely comes from one hard interface alone. It comes from the accumulation of dependencies across technical, compliance, and operational teams.
The main variables are usually:
-
Legacy system behavior and interface constraints
-
Quality of vendor documentation and sandbox access
-
Data quality and mapping complexity
-
Security, privacy, and compliance review requirements
-
Number of workflows that need user validation
-
Partner responsiveness during testing and certification
Early estimates should be treated as directional. A reliable delivery plan usually appears after discovery, interface analysis, and a first pass at test cases.
What skills does a medical integration engineering team need?
Strong delivery teams are cross-functional by design. Pure standards knowledge is not enough.
The team usually needs people who understand FHIR and HL7, backend and API engineering, cloud infrastructure, data modeling, security controls, test automation, and healthcare workflows in provider or payer settings. In practice, the highest-value engineers are the ones who can read an HL7 feed in the morning, review an IAM design in the afternoon, and still ask the right question about how a referral or prior authorization moves through the business.
That range is hard to hire for. It is also why integration programs stall when ownership is split across too many narrow specialists.
Can off-the-shelf integration platforms replace custom engineering?
Sometimes they should. Sometimes they should not.
Interface engines and integration platforms such as Mirth Connect, MuleSoft, Red Hat Fuse, and vendor-specific tools can reduce delivery time for routing, transformation, protocol mediation, and operational monitoring. They are often a sensible choice when the problem is repeatable, and the organization needs standard connectors fast.
Custom engineering still matters because the platform does not decide your canonical data model, exception handling rules, versioning policy, security boundaries, or product-specific workflows. Those choices determine whether the system remains maintainable after the first few partner connections.
The better decision framework is not build versus buy. It is where standard tooling reduces cost, and where direct engineering control protects product differentiation, compliance posture, and long-term operating cost.
Bridge Global helps healthcare organizations design and build connected platforms that can handle interoperability, secure data exchange, product delivery, and AI readiness in one engineering model. If you’re evaluating your architecture, planning a new integration program, or trying to modernize a brittle interface estate, explore how Bridge Global supports compliant healthtech delivery with product, data, and platform engineering expertise.
About Shreesha Chandrabose
Shreesha Chandrabose is a commerce graduate with a growing passion for content writing and digital media. With a curious mind and a creative approach, she enjoys transforming ideas into simple, relatable, and engaging narratives. She loves poetry, photography, and editing, and enjoys bringing ideas to life through words and visuals.
View all posts by Shreesha Chandrabose →